I will be posting over there in the next months. The difference would be that in the new blog I would be sharing not just the technical learning journey but also my life.
If you enjoyed (or were helped by this blog), please take a minute to follow me there. 🙂
Google has recently announced, that it is going to remove all sort of “expected ‘;’” errors from Android Studio in their next major update for Android Studio, in version 3. The previous sentence was a total pun, and it was actually the way I first interpreted their shift from Java code base to Kotlin. I don’t get the point, why is everyone hating the semicolon so much. Everyone keeps introducing new languages, and the most notable feature that distinguishes from the older languages is the semi-colon removal.
Enough gossip, now let’s talk somewhat reality into the post and have a look at what we have right now, which has caused somewhat tremendous amount of havoc on the internet, after those famous cat videos of course. 🙂
Is Kotlin new to Android?
Android now officially supports Kotlin programming language, along with Java and the native programming using C++ language.
Figure 1: Kotlin logo.
Typical question would be: Is this a new programming language to learn? Definitely no, and it is definitely not a new language for Android as well. Kotlin had been in the game since a while and if you have not yet heard about it, means, that you did not surf around in the Android world enough. Kotlin has been around for a quite long time and mostly, Android developers have already started using Kotlin language as their default language over Java. To me, the entire concept came as a new thing and at the first look, I was like, what the heck is this? Am I going to learn all of this now?
But, as the time passed, and I was to convert and see the difference of the languages; Java and Kotlin, I came to realize they shared most of the concepts and syntax, however, some of the stuff resembles Swift, and some C++ (or even C#) and some of the concepts were taken from “defensive programming”, and so on and so forth. Although the language was impressive, but the news that came on the Internet was not — as I did not watch the Google I/O 2017 so I did not know what happened, until I did watch it. I came to easily realize that the Kotlin language was not a new one, or that Google did not say that they are going to leave Java out and everyone would be required to program in Kotlin, they are both (Java and Kotlin, even C++) are all interoperable. Your current projects would continue to be in Java, until or unless you want to migrate the code base from one language to another one; new one. This provides the developers with a flexibility to migrate the code base, or work on the existing one: Your Android dev team can be split up into other sections, C++, Java and now Kotlin as well. Pretty interesting right (hehe, can’t imaging I said this…).
Figure 2: Android promoting Kotlin, or vice versa.
So, the benefits are really much amazing and counting, there would be much more by Google that you can wait for, to get and enjoy in the near future.
How to get Kotlin for Android
In my own opinion, it was a great step by Google to actually integrate the Kotlin language in Android Studio. Why? For several reasons:
Android developers were already using Kotlin language for their projects.
There was a plugin previously, that they needed to install to actually migrate the code base from Java to Kotlin. Also required some of the tweaking to the current build systems; to support Kotlin.
IntelliJ based system, and IntelliJ based language. Why not, eh?
Thus, Google announced that they will start shipping Kotlin support, built in. Android Studio 3 (which is, at the time of writing the post, a Canary version), would be the first of the versions to actually get the Kotlin packages pre installed and a complete support to develop Android applications in Kotlin language.
There are several other blog posts that you should definitely consider reading if you are new to the entire Kotlin concept.
Someone has to say, that this is a better language as compared to the older one, right? Sadly, I am not that someone. Too much of syntax simplicity, makes me “think”! If ignoring the common improvements that Kotlin brings, and having a look at what Android Studio has to offer, we can summarize this by saying,
“Android Studio speaks Kotlin”.
The most notable feature, as of Android Studio 3 is that now you can simply code your Java code from a Java class, and try to copy it in a Kotlin file, Android Studio will automatically convert that code from Java to Kotlin and print it there for you!
Figure 3: Dialog from Android Studio confirming to convert Java code to Kotlin.
I also got a chance to actually carefully study the current benchmarking, and some other references by other experts on Kotlin and/or the people who have had been working in the Kotlin environment, and I was to learn that you can actually love Kotlin for various reasons, and while being developed on top of (or beside) Java there are several ways in which Kotlin can be useful:
It has a better syntax, and a worse syntax in most cases.
Shorter and concise syntax, functions are example of this, but uglier use of generics, lambdas and the inheritance is shameful. Most of the features were “stolen” from various languages, and shamefully shown to be working.
Of course, if the code compiles, it means, the language succeeded! Hello world.
Acts as a wrapper around the JVM, so you can expect that it will not let you roam around the sensitive areas — areas where an exception will result in app not responding or app crashes.
Kotlin doesn’t bring much of improvements as performance counts, the reason being that the languages both compile down to the bytecode and that bytecode actually is what executes. A good program, with a better logic would run faster, but the language (Kotlin or Java) doesn’t much matter here.
On the other hand, Kotlin itself, brings around 7000 of extra methods to the overall API and somewhat an extra ~1MB of the APK file size — but Google suggests that you can minimize it, by the use of ProGuard or other services.
The compilation time is still almost the same, sometimes Java has a benefit of around 17%, sometimes Kotlin wins and it all depends on what you’re doing, not what the language has; besides, they both boil down to JVM bytecode.
Language improvements are the most notable feature; the first thing that you notice in this is the size of the programs that you will write. The lines of codes are really less.
But the thing is, your life as a developer would be much more simpler, neater and cleaner once you get your hands dirty in the programming fest with Kotlin as compared to Java.
Finally, there were a few bad things that I saw in Kotlin, some of us are living a happy life provided the existence of the “static” modifier, Kotlin doesn’t support that. Please review the references URLs and see “The Bad” section to know more on this.
If you are a beginner to Kotlin, then you would definitely be wanting to learn about the Kotlin language, fortunately, there is a tutorial and an online compiler that you can use. The online Kotlin resources provide a basic Hello World program that you can use for your own main learning goals. You should consider trying it out.
Secondly, there is also a feature provided where you can convert your Java code and learn what sort of Kotlin code gets generated to understand the typical Java ↔ Kotlin interoperability for the language tokens.
For example, I was using the online terminal and I convert the following code from Java to Kotlin,
public class Person {
private int age;
private String name;
public int getAge() { return this.age; }
public void setAge(int age) { this.age = age; }
public String getName() { return this.name; }
public void setName(String name) { this.name = name; }
public void sayHello() {
System.out.println("Hello, my name is " + getName());
}
public int older(int years) {
return getAge() + years;
}
private void breathe() {
System.out.println("I am breathing...");
}
}
The Kotlin code was like the following code,
class Person {
var age:Int = 0
var name:String
fun sayHello() {
println("Hello, my name is " + name)
}
fun older(years:Int):Int {
return age + years
}
private fun breathe() {
println("I am breathing...")
}
}
The screenshot of the web interface that provided this feature is as follows,
Figure 4: A GUI to convert Java code to Kotlin.
Provided that you forget about the semicolons, and a few other extra things, you will notice there are still a lot of changes to the language and some are interesting, some are unfathomable. Even by this very simple example of code you can easily realize that the Kotlin language,
Supports classes, and they are public (see the Java alternative code).
It supports the properties
Much more like C#, it does not have that getter setter style of encapsulating the private fields in public getters and setters.
The functions start with “fun”, but then become painful. 😀
Rest of the code is similar, you write the print line function, you can perform operations on the language’s primitive types (integers being added here).
You must provide the private modifier, public is default — or am I missing something?
I also have to figure out a few of the things here, most of the things are handy, and easy to understand, but major of the stuff is still confusing for me as to why I should use them, or why to stick to the stuff I already have.
So, do try it out, and also if you want to learn the bleeding edge technology, consider using Android Studio 3 and start building Android applications using Kotlin language, out of box.
Last year, I worked out and actually wrote about C# 6’s features, in a way that it would be easy to understand how they were actually created so that we can easily get a good understanding of the C# language, as it is evolving. Since a quite while, what happens in the language is that, where everyone else is trying to optimize the background code, the code that gets generated — what happens in C# context is, that the language gets optimized.
I was studying about async/await these days, what I figured out was, the feature itself was a syntactical sugar around the older ways of asynchronous programming. Only thing improved was, that you were never allowed to play around in the sand of memory.
Last year, when I was writing that post for C# 6 I figured that, most of the features were also improvements over syntax, to ensure language evolution, yet keeping things on ground — string interpolation for example.
While these changes can improve the way programs are executed, it still does not prevent any idiot to write bad programs, which I am going to do in this post. 🙂
So, to keep things short: In this post, I will be talking about the new improvements in C# 7, and what they are, how they get implemented and what you should understand before you actually start using them in your programs. I will also sum up the post by including my suggestions, and thoughts as to which of these features are helpful and which of them are not.
I will be going through a bit of IL code, and LINQPad will be used for this, so if you have an understanding of what the .NET IL code is, would be a good plus point for you, if not, then it doesn’t matter as I will explain the concept myself.
Important features to cover
C# 7 introduces several improvements to the language, and ignoring the .NET 4,7, there is still a lot of stuff to cover, but I will not be covering any of that stuff. I want to cover only a few of the topics because, the stuff is already way too much for one post. Anyways, the following list shows the important features of C# 7 that I want to experiment with:
Literals
Local functions
Tuples improvements in C# 7
Pattern matching cases
Async improvement — ValueType Task<T> object
Deconstruction
There are other some basic differences there as well, but most of them are improvement or additions to the stuff we already had looked at in C# 6, such as the expression bodied methods and members, so I will not cover them here at all. However, I might be covering entire C# 7 improvement course in a separate ebook for developers, keep a watch out for it. 🙂
How to use C# 7?
Some might say, just download Visual Studio 2017 Community edition and you will get everything of C# 7 by default. Fine, but there are some who cannot access these tools, updated IDEs, SDKs because of several reasons. Thus to sum up the post for them, I will give an overview of the ways that you can actually use C# 7 in older versions of .NET framework, with older versions of Visual Studio.
Most of the features are packages; Tuples feature is an extension package from NuGet, that you can install.
Most of the features, are syntactic sugars — just like the string interpolation — so you will still be able to use maximum of the features of C# 7 in older .NET framework.
But, Visual Studio 2017 Community edition doesn’t charge anything, and has some benefits packed; so do consider it. 🙂
Understanding the improvements
Ok, so now let us consider understanding the improvements one by one and see how Microsoft (or the community) actually implemented them in the language. Review the list above, I will be covering only the topics provided there, so you know which part contains which of the sections here, and will be providing some more tips, how-to and why-to in the sections themselves.
Literals
The first and foremost thing in C# 7, that most of the people are still trying out are the literals. Fair enough, most of the times the improvement this has, has nothing to do with more readability. I would not talk much more on this topic, instead would only provide my suggestions on the topic and then close it.
// At the moment C# supports
var dead = 0xDEAD;
var beef = 0xBEEF;
Now, the current literals, support the “_” character to separate the value itself, but of what use the following would be?
var dead = 0xD_EAD; // ? Did I mean to write DREAD? Nope.
// So, not much useful for me.
Secondly, let’s try it out on a numeric value,
var kms = 10_000;
The way, I see these values, what I feel about them is, they are like a blank field, or a template. Instead of this, what I would have personally loved to see in C# would have been the “locale” based separators for the digits.
var kms = 10,000; // Looks more natural.
Look, the way C# is providing this feature, is that this is just syntactic sugar. So, since this is provided by the IDE, why not use the current locale, and map the digits from their to the native types.
The “comma” as a separator is more natural in many ways. even, 0xAD,BC, would be more readable than 0xAD_BC. That seems as if I actually skipped a value there.
I agree that to some 0xAD,BC, might not be as much visible; but given that the “comma” is used as a separator in most contexts, it can be used as a digit separator as well — provided the context of its usage.
Visual Studio should be intelligent enough to actually integrate this feature with the current locale settings of user.
However, the problem with my idea is that it is based on the locale of the user, and not the standard, so in the cases where there might be teams working on the same project, there might be a mismatch breaking the entire build just because of a literal.
Local functions
The thing about local functions is, somewhat interesting to me. They are just the way any other function is defined, they generate the same IL code and take the same amount of time, the only thing is that they belong to the function itself, unlike to an object instance or a class type (as in static functions). So, let’s have a look at what local functions are in real.
Let us assume, that I have a function that processes the list of integers, and then returns something,
int Process() {
var list = new List<int>();
var sum = Sum(list);
int Sum(List<int> items) {
return items.Sum();
}
return sum;
}
At the first glance, this looks just like any other ordinary C# program, you provide the variables, set some functions and then return it; print it. However, this is just a sample function, which has state, a function and something to return to the caller. The function, in no way is different than the following code,
int Process() {
var list = new List<int>();
var sum = Sum(list);
return sum;
}
// Notice, that both are instance functions.
int Sum(List<int> items) {
return items.Sum();
}
Thus, what happens at the background is also similar, the IL generated by these methods is same.
IL_0000: nop
IL_0001: ret Process:
IL_0000: nop
IL_0001: newobj System.Collections.Generic.List<System.Int32>..ctor
IL_0006: stloc.0 // list
IL_0007: ldloc.0 // list
IL_0008: call UserQuery.<Process>g__Sum1_0
IL_000D: stloc.1 // sum
IL_000E: nop
IL_000F: ldloc.1 // sum
IL_0010: stloc.2
IL_0011: br.s IL_0013
IL_0013: ldloc.2
IL_0014: ret <Process>g__Sum1_0:
IL_0000: nop
IL_0001: ldarg.0
IL_0002: call System.Linq.Enumerable.Sum
IL_0007: stloc.0
IL_0008: br.s IL_000A
IL_000A: ldloc.0
IL_000B: ret
The only difference in the second case is the label used for the function block, and the call operation has the function name, instead of the g__Sum1_0. So, the difference in only the naming of these functions, otherwise they have common things,
They are instance functions
They perform same operations, generate the same IL code as well.
They can be used to wrap any task, that requires to be executed as needed.
While this is shown, there are a few differences to note here as well,
The local functions have access to the function local variables as well.
For external functions, you have to manually pass the parameters; or at least use ref, out parameters.
Local functions have direct connection to the variables of a function.
That said, there is another major point to talk about; the location of the function inside the function doesn’t matter. It is only the matter of taste, and C# would then generate the IL for that, so that the compiler knows where that function is. What I mean to say here is, you can actually return a value before even writing the local function, and C# would compile the code and make it work properly as well.
int Process() {
var list = new List<int>();
var sum = Sum(list);
return sum;
// Function here.
int Sum(List<int> items) {
return items.Sum();
}
}
The IL code for this is,
Process:
IL_0000: nop
IL_0001: newobj System.Collections.Generic.List<System.Int32>..ctor
IL_0006: stloc.0 // list
IL_0007: ldloc.0 // list
IL_0008: call UserQuery.<Process>g__Sum1_0
IL_000D: stloc.1 // sum
IL_000E: ldloc.1 // sum
IL_000F: stloc.2
IL_0010: br.s IL_0012
IL_0012: ldloc.2
IL_0013: ret <Process>g__Sum1_0:
IL_0000: nop
IL_0001: ldarg.0
IL_0002: call System.Linq.Enumerable.Sum
IL_0007: stloc.0
IL_0008: br.s IL_000A
IL_000A: ldloc.0
IL_000B: ret
Typically, the only difference is, if you write the “return val;” at the end, there will be a nop bytecode operation added to the IL, which as you may know is a no operation command, but might consume a cycle and so.
Local functions are instance functions
One other difference is that, you can easily create static functions, but however, the local functions cannot be static functions. Even if that parent function is a static function, the local function cannot be a static one. I don’t actually understand this one thing, why… But perhaps, the context itself is static, and the function would ultimately end up being static… Or what, but, let’s just say it works. 🙂
static int Process() {
var list = new List<int>();
var sum = Sum(list);
return sum;
// Function here.
static int Sum(List<int> items) { // CS0106: The modifier "static" is not valid.
return items.Sum();
}
}
In most cases, the local functions seem to be helpful, but in major cases this might be an extra region to cover.
Local functions as lambdas
One final thing about local functions, is that they can be easily created as lambdas. So the code that we have,
int Process() {
var list = new List<int>();
var sum = Sum(list);
return sum;
// Function here.
int Sum(List<int> items) {
return items.Sum();
}
}
Can be easily rewritten to the following one,
int Process() {
var list = new List<int>();
var sum = Sum(list);
return sum;
// Function here.
int Sum(List<int> items) => items.Sum();
}
Believe it or not, the change has a huge performance improvement over the older (function) way. The lambdas are definitely stronger. As we move onwards in the article, you will see how much of the concepts are being taken from the function programming… Tuples is one of such.
Tuple improvements in C# 7
As you may know, tuple is a concept of functional programming, and are really very powerful and useful types; C# guys don’t know much of it, but function world such as Haskell have been using them for a while. Previously, System.Tuple type was used to create the tuples. Before, I actually go down, let me tell you that a tuple doesn’t only mean that you can, “return more than 1 value from a function”. That is just one the uses where a tuple proves to be useful, not all of it. Remember, that I said it comes from functional world, in that world there are no objects and thus no classes and no instances. Thus, when you have to store something you would typically be using a tuple, that would show a record, or an entity — not an object.
Tuples have their own benefits, and objects have their own. In the older versions, they were created as a type of tuple, a structure. However, improvements have come and they are not a part of the C# language syntax, so you do not have to write anything extra, and you still get the benefit of that. Also, the tuple is now a System.ValueTuple instead of the System.Tuple.
So, now let us see what they are and how they are useful, or not… 🙂
void Main()
{
var person = GetPerson();
Console.WriteLine($"{person.Item1} is {person.Item2} years old.");
}
(string, int) GetPerson() {
return ("Afzaal Ahmad Zeeshan", 21);
}
// Output
// Afzaal Ahmad Zeeshan is 21 years old.
In the code above, what I am doing is, I am creating a separate function. A function that returns a tuple type; a tuple is wrapped inside the parenthesis, and has a type for each element, the name of the elements is conditional, which defaults to ItemN.
Similarly, what the code does, is that it gets the value from the function and prints it on the console. Studying the IL code for this would give a more in-depth overview of the tuple type,
IL_0000: nop
IL_0001: ldarg.0
IL_0002: call UserQuery.GetPerson
IL_0007: stloc.0 // person
IL_0008: ldstr "{0} is {1} years old."
IL_000D: ldloc.0 // person
IL_000E: ldfld System.ValueTuple<System.String,System.Int32>.Item1
IL_0013: ldloc.0 // person
IL_0014: ldfld System.ValueTuple<System.String,System.Int32>.Item2
IL_0019: box System.Int32
IL_001E: call System.String.Format
IL_0023: call System.Console.WriteLine
IL_0028: nop
IL_0029: ret GetPerson:
IL_0000: nop
IL_0001: ldstr "Afzaal Ahmad Zeeshan"
IL_0006: ldc.i4.s 15
IL_0008: newobj System.ValueTuple<System.String,System.Int32>..ctor
IL_000D: stloc.0
IL_000E: br.s IL_0010
IL_0010: ldloc.0
IL_0011: ret
If you try to pay attention, you will see that all it does is, it gets the value and prints it as soon as the value is loaded onto the execution stack. However, I always thought perhaps, tuples were never needed and that the current types were enough to be worked around with, but if you try to unwrap the values and do something on them then, you will have a drastic change in the performance.
var (name, age) = GetPerson();
Console.WriteLine($"{name} is {age} years old.");
This code is a bit more readable for the people, but has an extra overhead for the program because now the program also has to push the variables on the stack.
It loads the tuple type from the function.
Maps the types to the named variable.
Notice that the name and age variables are of different type, but they are both sharing the var type.
Then after this, it continues doing the same work that it was.
So, the thing is, the default tuple ItemN type does have a less readability but it gives you extra performance if you’re needing.
As for the IL, here is the IL for the code sample above,
IL_0000: nop
IL_0001: ldarg.0
IL_0002: call UserQuery.GetPerson
IL_0007: dup IL_0008: ldfld System.ValueTuple<System.String,System.Int32>.Item1
IL_000D: stloc.2
IL_000E: ldfld System.ValueTuple<System.String,System.Int32>.Item2
IL_0013: stloc.3
IL_0014: ldloc.2
IL_0015: stloc.0 // name
IL_0016: ldloc.3
IL_0017: stloc.1 // age
IL_0018: ldstr "{0} is {1} years old."
IL_001D: ldloc.0 // name
IL_001E: ldloc.1 // age
IL_001F: box System.Int32
IL_0024: call System.String.Format
IL_0029: call System.Console.WriteLine
IL_002E: nop
IL_002F: ret
IL shows, that there is no need for duplication of the data, no need for extra stack pushing, plain processing is going on down the road.
No limit on the length
One more thing to realize here is that the older types, have a limit on the types that you can use. Such as, a 7-tuple type is Tuple<T1, T2, T3, T4, T5, T6, T7>, but however there is no limit on the length of the tuple typing in this case, you can have any number of elements in the tuple. Interesting improvement!
So, if your code requires a type that has like around 11 elements, you can use this without any problem at all.
Finally, there is no limit on the type of parameter to be used, you can use the local variables in the tuple. However, once again, the naming of the tuple elements is just the personal sort of taste that you can, or can not prefer so I won’t talk about it any further.
Also, using a custom value typed structure also has some overheads, so if you want to create a separate object of that type, that is also not a good option. In most cases, I myself am going to enjoy using the tuple types in C#.
Pattern matching cases
Pattern matching is the use of current structures in C#, to initialize the variables, and check the conditions in one place. For example, have a look at the following code,
void Main()
{
var types = new object[] { "Afzaal", 21, 4.5d };
Process(types);
}
void Process(object[] list) {
foreach (var item in list) {
if(item is String) {
Console.WriteLine($"{(string) item} is String type.");
} else if(item is int) {
Console.WriteLine($"{(int) item} is int type.");
} else if(item is double) {
Console.WriteLine($"{(double) item} is double type.");
}
}
}
// Output
// Afzaal is String type.
// 21 is int type.
// 4.5 is double type.
This code has a condition that checks if the type is matching, and then after that, casts it to the proper type to show the results. Whereas, if we use the C# 7 way of doing this, we would get the following results,
void Main()
{
var types = new object[] { "Afzaal", 21, 4.5d };
Process(types);
}
void Process(object[] list) {
foreach (var item in list) {
if(item is String str) {
Console.WriteLine($"{str} is String type.");
} else if(item is int i) {
Console.WriteLine($"{i} is int type.");
} else if(item is double d) {
Console.WriteLine($"{d} is double type.");
}
}
}
This code has somewhat better readability, as compared to old one, and also saves us from an extra cast, because that is taken care of by the IL in the background. Making it easier for us to write the code, the same is the case for the switch statements, as example, let’s see how the integer check works in this case,
Here, it captures the value from the list, checks if it is the instance of the “Nullable” type of the object, then gets the value by unboxing it and then rest of the stuff is the same process, or formatting the string and writing it. The thing is, we get saved in many ways, and the readability has improved.
As for the switch statements, the following is the syntax,
switch (obj) {
case Person p:
break;
case Shape s:
break;
default:
break;
}
The improvement is, instead of having a primitive type here, you can now match the object type there — which is the same as I have already shown using the example of if…else block, also you can use the when block to make sure that a case gets evaluated only if the condition is met, providing you with a good way of range based switch statement.
void Process(object[] list) {
foreach (var item in list) {
switch(item) {
case String str:
Console.WriteLine($"{str} is of String type.");
break;
case int i:
Console.WriteLine($"{i} is of int type.");
break;
case double d:
Console.WriteLine($"{d} is of double type.");
break;
}
}
}
This gives the same output, and works like a charm in the case. Also, if you would like you can add a condition to evaluate an integer value or any value based on a condition. Personally, I loved this feature as well because there were cases where one of the structures was unable be to be used, and one was not efficient… However, these improvements are bridging the gap actually.
Async improvement — ValueType Task<T> object
To most, this might not come as a surprise, but to those who do some hardcore multithreaded programming and rely on this, for their job, the new improvement is just amazing. What this means, is that you can now easily use the ValueTask. This type actually exists in the System.Threading.Tasks.ValueTask, but comes from an extension library from NuGet; System.Threading.Tasks.Extensions. You can easily download it for your own project, and get started using the new type.
However, there are a few things to note:
This is a value type, instead of a reference type.
The major reason was that, a reference type, as the name suggests, required to be instantiated and an object was created.
However, the value type, if is known, would only require a stack push… No other stuff required.
Even the documentation suggests, that you should consider using the Task<T> type instead of the ValueTask<T> type. Only if you are aware that there is a performance improvement, then do that, otherwise keep using the Task type.
However, deep somewhere, I do believe Microsoft is working on bringing some improvements to the package and will make this even better. Until then, let’s talk about the next topic in C# 7.
Deconstruction
This is a very interesting topic in C# 7, but I left this one for the last, so that I can easily explain the core concepts that are required, such as the Tuple types, and some other extra features in C# 7, such as ref and out parameters.
The deconstruction, and destructors are two different things, and must never be intertwined under any circumstances. The deconstruction is a language feature, which, provided a function converts the runtime object to a tuple. See, how important the concept of tuples was before this section.
The function itself is,
void Deconstruct(out string param1, out int param2) {
// Set the out parameters here.
}
Without this function, the language won’t be able to provide you with the deconstruct feature, and you would typically have to write a personal function that does this. If we create the function and then execute the following, it works,
void Main()
{
var person = new Person() { Name = "Afzaal Ahmad Zeeshan", Age = 21 };
var (n, a) = person;
Console.WriteLine($"{n} is {a} years old.");
}
public class Person {
public string Name { get; set; }
public int Age { get; set; }
public void Deconstruct(out string n, out int a) {
n = this.Name;
a = this.Age;
}
}
Removing the function cause an error, that tells the programmer that only a type that has the “Deconstruct” function is able to undergo a deconstruction, otherwise, add some helper functions etc. If none, then you cannot use this in your own code.
The properties of the objects that get returned are depending on what you want to create with the object. Also, you would require to use the tuple to store the values; thus understanding how they works, is a good start for you.
Final Words
Although C# 7 has some great improvements, be it a syntax improvement, or the language improvement. I am impressed by some major changes, but I was annoyed by a few changes that were never required, or should have been left to the packages were supplied built it.
Most of the features of C# 7 are package based, and thus they require a package to be installed from the NuGet libraries. Whereas, a few of the improvements were installed natively — that literal one is such, and I hated these changes… Whereas, the changes that I might have enjoyed were skipped — tuples, value task etc. They would have been added to the language.
Also, to the reader, I did not cover most of the improvements, because most of them I already did cover in the previous post of mine and were similar thus I left them. However, this post was meant to give you a brief overview of the improvements in C# 7. I hope you enjoyed reading the improvements and which are just magic tricks. 🙂
As the title suggests, this post is a personal recommendation for the users of Microsoft Cognitive Services, the services that provide a cloud-based subscription-based solution for artificially intelligent software applications, with an any team, any purpose and any scale commitment. We all are aware of the fact that Microsoft is investing a lot of man power, promotion and commitment in Azure nowadays and almost every of their solution is hanging around the verge of Azure and one way or the other they come back to a same conclusion, that the solution can be purchased as a Software-as-a-Service from Azure — there are many other names, Platform-as-a-Service, Service-as-a-Service, choose yours from the pool as liked.
In this post, I am going to cover up the most important points that your team should understand before migrating to the Microsoft Cognitive Services.
Background of Microsoft Cognitive Services
To any of you, who have no idea of what Microsoft Cognitive Services are: Microsoft Cognitive Services are a bundle of services, provided by Microsoft to individuals, team, and/or organizations of any size and any scale to provide services that require complex machine learning or artificially intelligent responses.
It is a tough task, to accomplish the machine learning, and with just one wrong input your entire algorithm can go to {add a slang here}. Microsoft is providing the service, where you only have to provide the inputs for the algorithm, and you get the output. Microsoft itself manages the way algorithms are going to be fine tuned, or the performance of the algorithms, you don’t worry about that.
It is a subscription based service, provided as a service in Azure now. In this post, you will know how likely is Cognitive Services service of any help to you!
Tip #0: Ask (Convince) your boss
Microsoft Cognitive Services are tested against thousands (if not millions) of users, data records and entities and the algorithms is really a concrete! You cannot meet the level where Microsoft Cognitive Services are really providing the services, the reason is that Microsoft has partnered with quite a lot of academics professors, indie developers, teams and organizations and even most of the times online surfers show up and share some data to the cloud — all of which is under a license and Microsoft asks for permission, I am not here to cover up the license terms anyways.
Get the permissions, so that we may continue on this post. 🙂
Tip #1: Take only what you need
Cognitive Services is a library of services, there are a lot of services already added to the library and many are being added every month. But that doesn’t mean you should consider all of them, or even half of them. They are all categorized under different sub sections, that contain collective services provided by Microsoft CS,
Vision
This set of services contain face APIs, such as recognition and tracking.
It also provides services that can extract features from faces such as age, emotion detection.
It also provides computer vision, that can allow users to perform OCR functions on the images.
Speech
Allows your users to trigger functions based on their vocal commands. — Natural language processing.
Speaker Recognition — bleeding-edge technology!
Speech to text, and text to speech services.
Language
Allows to perform linguistic analysis of the text.
You can use the previous services to perform analysis on the photos as well, so that you read the text using OCR and then analyze the text.
LUIS (Language Understanding Intelligent Service) is the new Jarvis!
Knowledge
Recommender systems.
Anything that requires complex academic, or research stuff.
Search
The old Bing APIs are now provided here…
Likewise, you can see that these are the categories, and even these categories have different API sets and services that you might want to consume. It is up to you, to select which one you need.
Let me put this simply, if all that you need to do is, read the text from images, convert them to speech and communicate. Then all you need to purchase is, “Computer Vision API”, and “Bing Speech API”. Your application won’t need the rest of the services. LUIS can be added finally to support the communication later on.
There will be more services, and you can always add up more services. But if you are no longer using a service, or your application is not related to a service, there is no need to purchase a key for that service.
Tip #2: Keep everything in Azure
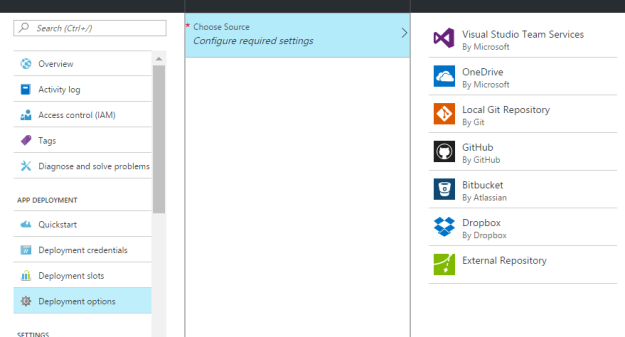
Microsoft CS are provided from different areas (all Microsoft properties), such as LUIS can be accessed through luis.ai, and vice versa. But you should keep the family tight, and keep all of the keys and resources on Azure. So that you can manage everything from a single subscription, instead of having to look at various different accounts to configure and consume the applications.
Microsoft CS supports REST-based API (and we will cover this in a later tip below), so it is very easy to add the keys to the URL and start consuming the services.
You can manage all of the keys from within Azure, just head over to the Cognitive Services blade and open up the application that you want to get the keys for. Under the “Keys” section, look for the keys that you can use to authenticate the requests.
Figure 1: List of the Cognitive Services associated with the account.
I have 4 services active, that I can access in the Azure through REST APIs. How simple that is! You can add more keys, add more services, update the keys… All from within Azure! By the end of this post, you will realize the importance of this tip.
Tip #3: Get most out of REST API
Microsoft CS Azure endpoints are provided as REST API endpoints, that you can access through any HTTP client — even a web browser. The REST API, since working on HTTP protocol, allows you to make the best use of HTTP protocol and send/receive information. Currently, Microsoft CS supports two ways of uploading the information to the cloud,
URL based
Binary data base
These are the two ways that you can deliver the content to Azure for processing. Apart from this, the only required header for the request is the subscription key, added to the header of “Ocp-Apim-Subscription-Key“, which is processed first and the rest of the stuff is processed later based on the subscription information.
Example
Now let me show you a little example in WPF application, of consuming the Computer Vision API to detect what the image is all about. Azure will result in a complete sentence that explains the image, and the objects in the image as well as the task being done.
The XAML code for the WPF application is as below,
Figure 2: WPF application running, with no image selected.
As for the backend code, the C# code was written as following,
private async void btn_Click(object sender, RoutedEventArgs e)
{
using (var client = new HttpClient())
{
// Request headers
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", "<the-subscription-key>");
// Request parameters
var uri = $"https://westus.api.cognitive.microsoft.com/vision/v1.0/analyze?visualFeatures=Description";
// Request body
if(fileName == null) { MessageBox.Show("Select a file first."); }
byte[] byteData = File.ReadAllBytes(fileName);
using (var content = new ByteArrayContent(byteData))
{
content.Headers.ContentType = new MediaTypeHeaderValue("application/octet-stream");
var response = await client.PostAsync(uri, content);
}
rslt.Text = await response.Content.ReadAsStringAsync();
}
}
private void slct_Click(object sender, RoutedEventArgs e)
{
OpenFileDialog dialog = new OpenFileDialog();
if (dialog.ShowDialog() == true)
{
// Something happened
fileName = dialog.FileName;
var source = new BitmapImage(new Uri(fileName));
image.Source = source;
}
}
Likewise, the output of this code, once worked was,
Figure 3: Image selected and response captured from the Azure.
Like seen, this is the result, which can be mapped to a JSON object for storage or for further processing of the requests.
Tip #4: Timing is everything
Our interest in Microsoft CS is only possible if it can guarantee that we get results in a timely manner, for example if we invest Microsoft CS in the security applications, then users should be provided with results in a timely manner and the lagging may cause us to reconsider stuff around.
So, I wanted to show the time of the request as well, to demonstrate how this all works. For that, I modified the code and the following changes were applied,
Stopwatch watch = new Stopwatch();
watch.Start();
response = await client.PostAsync(uri, content);
watch.Stop();
rslt.Text = $"Request took {watch.ElapsedMilliseconds} ms to complete, for {byteData.Count()} sized byte array.\n\n";
rslt.Text += await response.Content.ReadAsStringAsync();
The effect of this was that I was able to determine how long does it take to process and return the result.
Figure 4: Application showing the time as well.
Look at the top paragraph, it says, “Request took 3519 milliseconds to complete, for 33282 sized byte array.” Which means, that to process a file of round about 30 kB it took around 3.5 seconds. There are other factors that caused the delay, such as my internet connection. Secondly, a larger image file will take more time, and a smaller image will process quickly but with errors.
There are a few things that we learn from this…
The timing of the Azure is not a big factor, the factors are
Our own Internet connection
The image itself
Type of processing to be done is important
Processing a sound track of 15 seconds with low quality vs a sound track of 1 min with high quality, are never going to end up with same time.
CDNs may or may not help in this case
Finally, the requirements differ from the API to API, that is why I will not talk about the recommended image size. But, you can increase the performance of the applications by uploading the files directly to Azure, because Azure is always going to download the file from the URL as well to process it. So, why not upload it directly?
Tip #5: Security
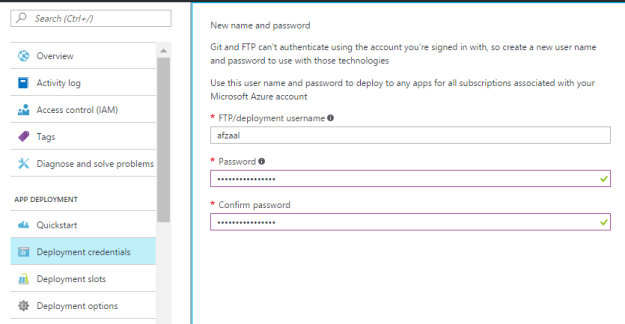
The keys for your application are really crucial. And if they are lost, or accessible to anyone, then you are responsible for what happens — in worst scenarios, they may use your own resources for their own use, and charged will be you!
Remember Tip #2, if you followed my advice, you would now be able to easily change the key if you feel someone has access to the keys.
Figure 5: Keys shown for the Microsoft Cognitive Service purchased from Azure.
Otherwise, you can use other ways to hide the keys if you don’t like updating the security keys every month. Some include, like storing the keys in secure areas, such as the Key Vault of Azure or any other place where none can access… But, what if someone does access? 🙂
In many ways, things can go wrong, thus it is my recommendation to update the keys every month. Note that you can use either Key 1 or Key 2, and you can update both the keys independent of the other.
Reminder: Just when you were reading this post, I went back and regenerated the keys… Took only 4 seconds to regenerate the both. 🙂
Final Words
I have no words, seriously. I am out of words at the moment, so, I hope you enjoyed the post. 🙂 See you next time.
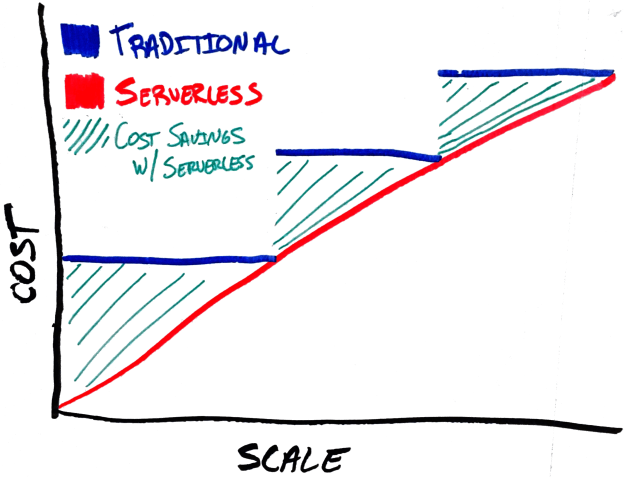
It has been quite a while since I last published anything about Microsoft Azure, so here is my next post about Microsoft Azure. The subject itself could’ve been for the last post in the DevOps category, however this seems to be one of the initials in the category. So, what I want to cover in this post is that… Most of the times, Continuous Delivery comes handy when you really want to make things a bit automated. However, CD is not that much simple to consider. Most of the times, there is authentication required on the machines where your application is going to be delivered etc. Continuous Integration on the simpler hand, is just the process to trigger build for every change in the system.
Continuous Delivery gives the most hard time to any DevOps practitioners. The reason behind that is that CD requires not just the release information, but instead it also needs where to deploy the application, most systems require authentication/authorization in order to deploy or update the applications. That is why, this topic is the toughest in DevOps, I believe.
To keep things simple, I will just create a simple ASP.NET Core application, and then I will deploy that application to Visual Studio Team Services environment, where it will be:
Built using ASP.NET Core build system
Deployed to Azure App Service “Deployment Slot“
Swapped to the default web app slot
These are the steps that we are going to take in this post, to learn how we can solve the CD problem with VSTS for Azure and ASP.NET Core web applications.
Note: If any of the images are blur, or harder to read. Right-click the image, and open the image in a new tab. Finally, remove the query string (for example, “?w=625&h=113“) and then reload the image. That query string filters and requests a smaller image. You can download the image in full resolution.
Deploying a simple web app
So, open up the terminals and type the following commands,
$ cd your_preferred_directory
$ dotnet new -t web
$ dotnet restore
What this will do — if you don’t know — is that it will create a new project, and setup the development environment for you locally. After this step, — I recommend using Visual Studio Code — you should open up the IDE and start programming in it.
$ code .
I will initially upload the default web application, and then later I will shift the content to the slots and deploy the latest changes to the production.
So, let us just go ahead and create a git repository inside the same directory. Later on we will publish the project to a remote repository of our VSTS account’s project. You would require the execute the following commands for that,
$ git add .
$ git commit -m "Committing the changes to repository".
$ git push https://git.yourserver.com/repository_path.git
The above commands, are hypothetical and you should fill in with your own repository information here. But they will work exactly the same.
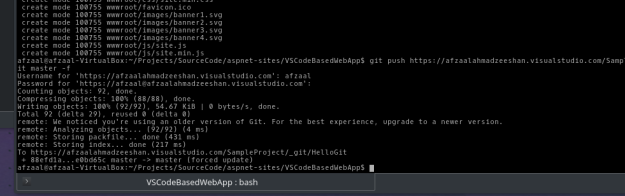
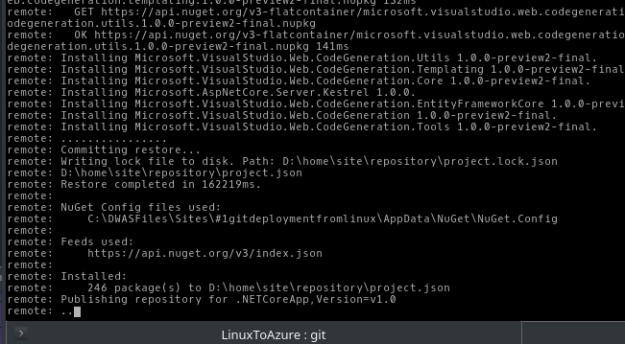
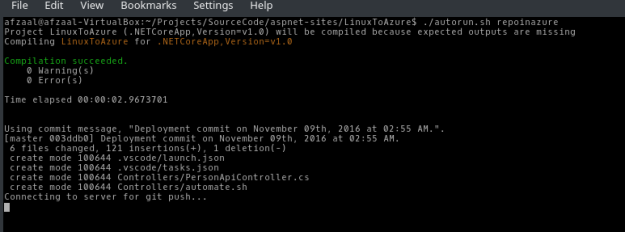
I did the same, and targeted my VSTS project repository to publish the code. Once the code was published, the build system was triggered automatically.
Figure 1: Publishing the changes to VSTS repository.
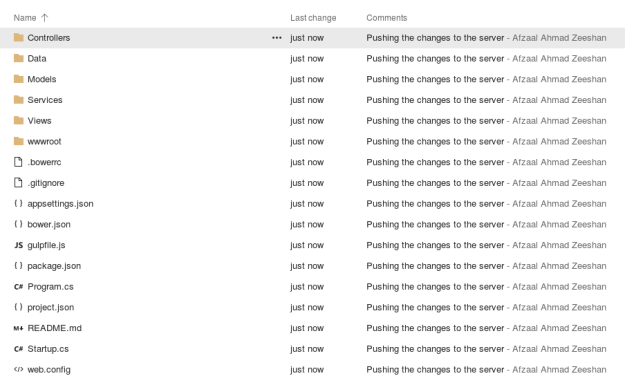
That content gets uploaded to the VSTS repository,
Figure 2: Content of online repository in VSTS.
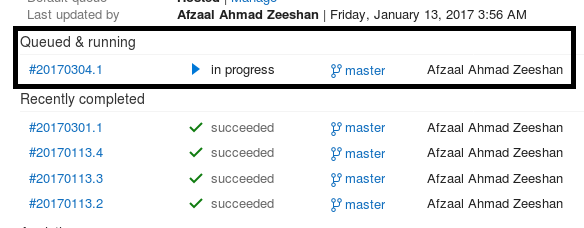
Now, since our code has been modified, the continuous integration system triggers and starts to build the project since there were changes.
Figure 3: Build triggered and running in VSTS.
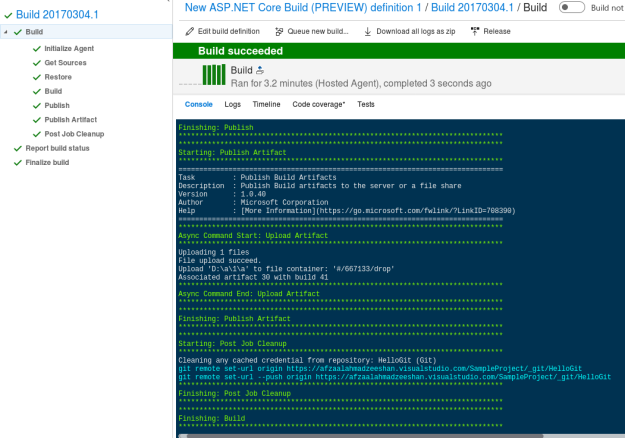
That is currently the build that our change triggered and queued. Now, the build system is for the ASP.NET Core provided by Microsoft in the VSTS. We can use other build systems, or create our own build systems based on the frameworks, or languages that you are using. However, since ASP.NET Core was the default here, I used that.
Figure 4: Build results for the latest changes in the repository.
After a few steps that are required in the build system, it would finally publish the built executables and other resources, to an artifact folder from where other processes can copy the content easily.
Now since we are using the CD system, the trigger of a successful build would also trigger the deployment, to a location where we have told it to.
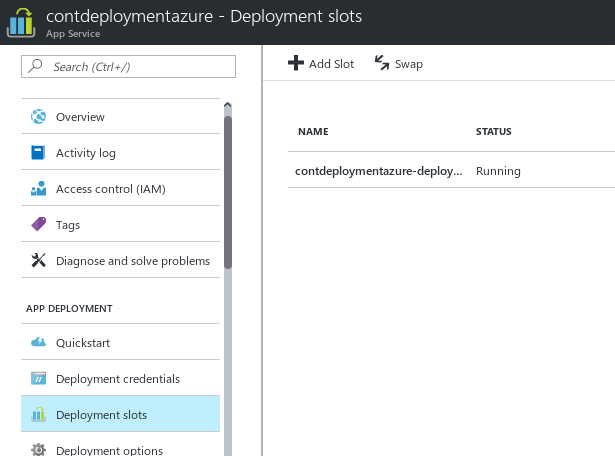
Using Deployment Slots
The reason why you should prefer using Deployment Slots is that, they are wonderful! Only Azure supports Deployment Slots, whereas on the other vendors you require to have two separate machines, and then you connect them across. Whereas on Azure, things are different.
Deployment Slots are submachines in your own machine — or service.
They provide an identical environment and configurations for your application to work.
Deployment Slots mimic the production environment, so, it is as if you were testing the application on the production environment.
The swapping process takes zero downtime! Load balancers allow Azure to switch the IP address mapping to the virtual machines or services internally.
No requests are dropped in the swapping process.
Thus, I also used the deployment slots in Azure, as they allow a lot of stuff to be managed easily. And it my own recommendation, to never deploy the applications directly to the production environment, as there needs to be some testing system that confirms that everything runs perfectly on the production environment as well, and not just on the testing environment.
So, that is what I did. I created a deployment slot in the testing App Service for this post.
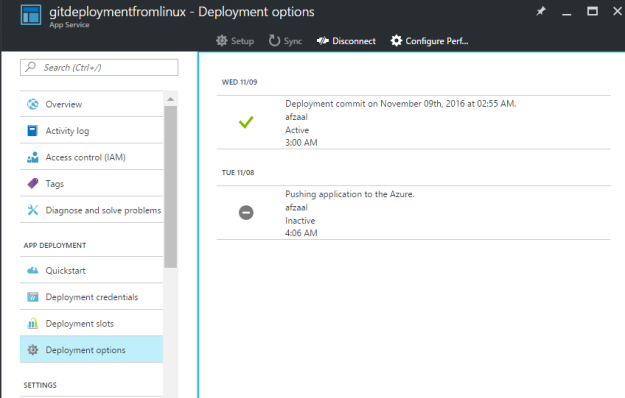
Figure 5: Deployment Slot made active in the application to store and stage the latest version of application for testing purposes, and booting purposes.
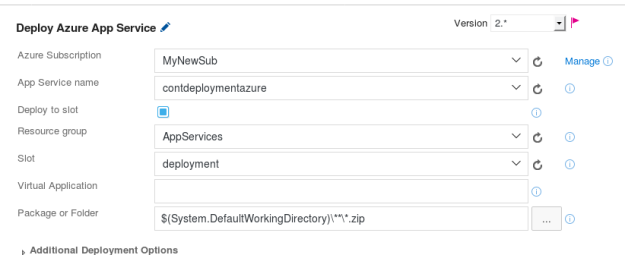
Then, once that was done I went onwards to modify the release system and ensure that the release was performed to deploy the application to the deployment slot, instead of the production slot.
Figure 6: Release settings for our Azure App Service.
The “Deploy to slot” option configures whether to deploy to a slot, or to the production slot. So, now that our release is also managed the next step in the toolchain was to deploy it, and since our build was successful the VSTS automatically triggered to deploy the application to the Azure Deployment Slot.
Figure 7: Release processing the latest build and deploying the application to Azure.
Pay close attention to the picture above,
It got triggered automatically (see the Description column).
The build that was used to fetch the artifacts is also shown.
Time and the author is also shown etc.
After this, the application gets deployed to the server.
Preview of the application
The first preview of the application is the following one,
Figure 8: Deployment Slot application preview.
This is the preview of the application under deployment slots. If you look at the URL, you will notice “-deployment” appended to the URL, which means that this is the preview of our slot, and not the application itself.
Benefits? Quite a few…
We can run all sort of tests to check whether the latest build work properly or not.
All of the dependencies get loaded up before serving any user. “Warms up the slots”
Users don’t feel that the website was updated, instead they just see what’s improved!
To update the production slot, all we need to do is, click a button.
In case of any problem, we can roll back the latest build… Even from a production slot!
These are a few of the benefits that I have found in using Deployment Slots and which is why I personally recommend using Deployment Slots instead of the production slot, each time. Secondly, you can provide multiple slots to different teams and every team will work separately on their own environment testing their own stuff.
Updating the application
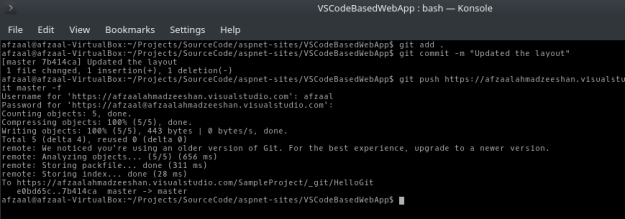
Now that our application is running, let us see how quickly can we update the application after a change. So, what I would be doing is I will be updating the navigation header for the site.
You might have noticed, what I changed? (Look for “Updated!” in the middle of the code above).
Figure 9: Committing the latest changes to the local repository.
This would update the local repository and then we can update the remote repository, to reflect the changes in our project’s repository. That step was similar to what did previously, just publish the changes to the remove repository.
Figure 10: Pushing the changes to the server for deployment.
So, that change was pushed to the server and that change then triggered our toolchain for build, release and deployment for the ASP.NET Core web application. What this did was, that it
Updated the remote repository.
Triggered the build automatically — Continuous Integration.
Triggered the release automatically, if the build succeeds — Continuous Deployment.
Finally, publishes the application where it has to go live.
So, the rest of the stuff was similar to what we had previously. Same build procedures, same release cycles and then finally everything goes to the Deployment Slots.
Swapping: Deployment Slots to Production Slots
At this moment, our application is properly running in the deployment slot! However, we need to swap the slots and then our users would be able to see the live updates. First of all, let us see how the updates changed our website then we will move onwards to update the website itself.
Figure 11: Latest updates on the Deployment Slot.
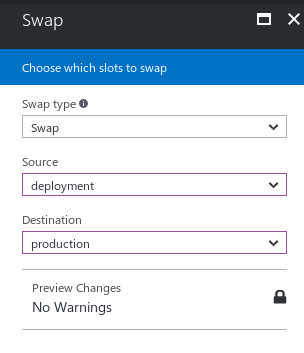
That is the deployment slot, and now we can move onwards to apply the changes to the production slot. For that, we can select the Swap option from the Deployment Slots blade, that option lets us choose which slot goes where.
Figure 12: Swapping the slots blade.
This order matters a lot, the Source should be, where your recent updates are, and the Destination should be where they should go! Now remember, although internally there is just a traffic shift from one source to another, but in real if the order gets messed up… The results are undefined. I have myself tried to play around with it and it gets messed up really very much. So, do remember, that order is everything! 😀
Finally, when we go back to our application website, you will see that the changes are now living there…
Figure 13: Preview of the production slot on Azure.
And the Deployment Slot gets the content of this application itself — the default Azure App Service page.
Summary and Final words
So, in this post we solved a few things out. First of all, we saw how CD gets to be the toughest IT part in DevOps (IT because there are some other tasks, such as user management where you get to face a headache of customer requirements and error management etc. :D). Then we moved onwards to manage the Visual Studio Team Services in order to apply the automation across the steps and stages of App Life Cycle.
Then, we saw how Azure Deployment Slots can help us get the most out of the testing systems and make sure that everything, I repeat, everything is working properly.
What’s next?
Here is the assignment, notice that I mentioned that you can swap the Deployment Slots? There is a way to automate that as well, how? Using Powershell! You can easily use Azure PowerShell on Visual Studio Team Services to automate the swapping process as well. That way, you can run some tests on the production environment and then let the cmdlets do the rest of the job for you as well.
Azure PowerShell also would let you migrate the website back if you feel that the website is not performing well.
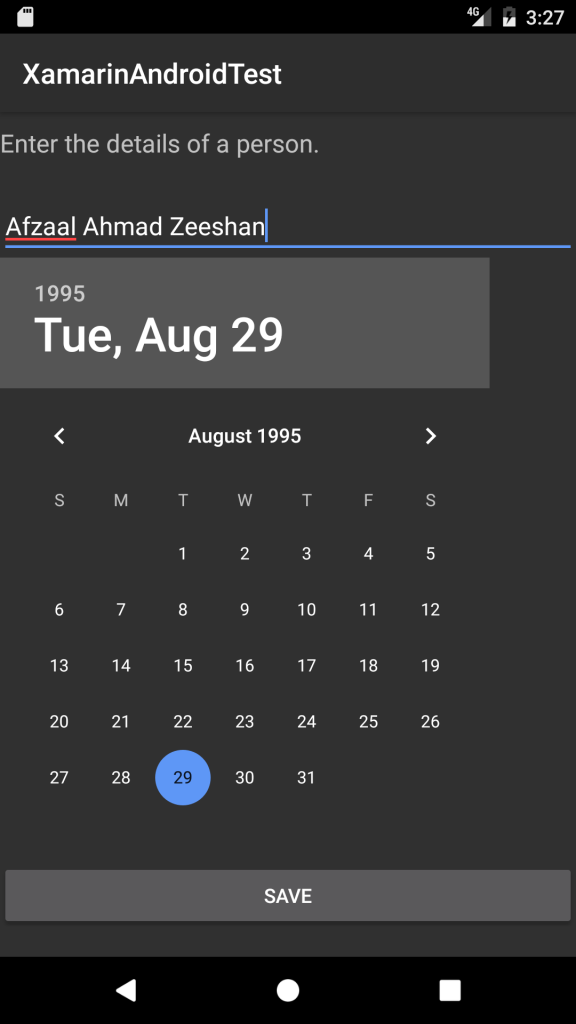
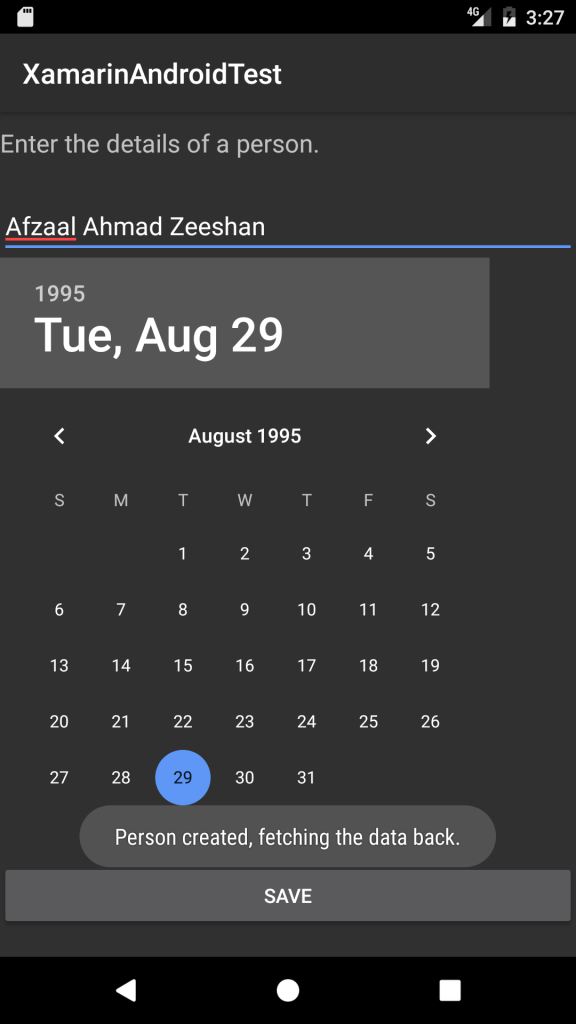
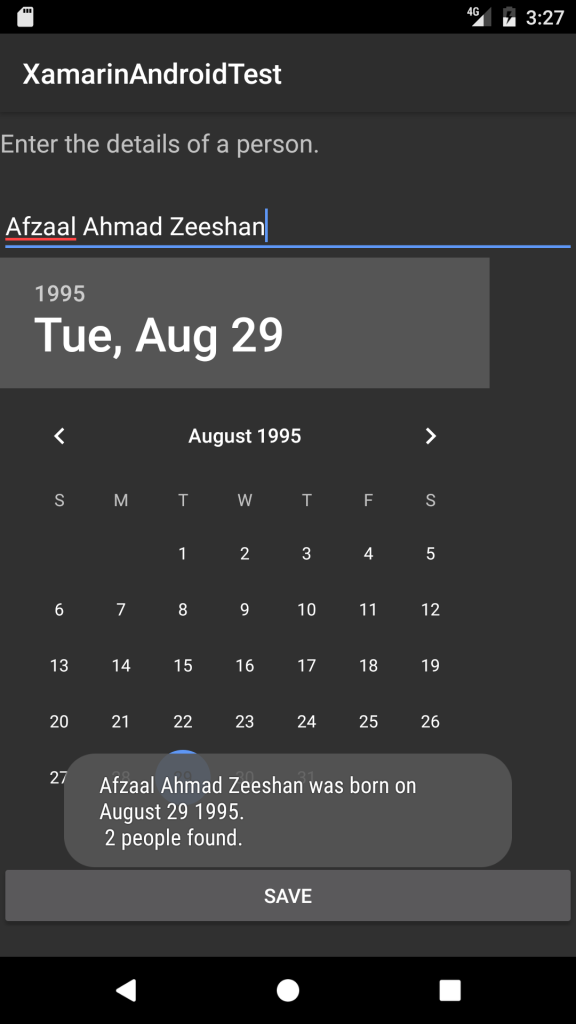
This is my, well, 3rd or 4th post on Xamarin and this one might be a bit critical in its topic or subject matter, so if you have been pulling your hairs off these days, this post is for you. Basically the purpose of this post is to provide you with a post that has most commonly faced issues, and their solutions attached. I personally faced quite a lot of issues with Xamarin. The problem was not that I was a beginner in Xamarin. The major problem was that it was all working before, but right after a reset everything was giving me an error. Even worse was that, there were no solutions at all. Every solution was like, “Reinstall Xamarin”, “Reinstall Android SDK”, “Remove the space in the Android SDK path”. Even the most authentic of the resources were not providing the working or at least “sensible” solution to me. So I thought I should write a complete post, sharing the reality based solutions, and not just, “install this, install that” sort of stuff that does not help anyone at all.
Installation of Xamarin
Installation of Xamarin itself is a bit confusing and problematic in real, for beginners. If you have had ever worked with Xamarin previously, then you might know where all the plugs go, but for a beginner the experience is painful and many leave in the start — let alone middle as the least.
The initial location where Xamarin installs the Android SDK is, “C:\Program Files (x86)\Android\android-sdk“. A few things to consider here:
There is no problem with the space in the path. Spaces are a problem only in the cases when you are going to program using NDK (Native Development Kit), otherwise they do not cause any problem. I am also using a path with space in it and it does not cause any trouble.
Before anything at all, I would recommend that you run the Android SDK by running:
Either “android.bat” file as Administrator.
Or by going to Visual Studio and running Android SDK from the Android toolkit tray. It will request Admin access itself.
Note that you need to run SDK Manager with Admin access. Otherwise, it will not work. Worse, it will give you errors of “Unable to move directory…” and later, it will delete the “android.bat” file and you will have to download and install Android SDK once again. Painful.
It can be helpful to use the Android SDK installed by Android Studio in cases where you are lacking enough HDD space on your machine, but it is my own recommendation to not use that. The reason is that in case Xamarin messes up, Android Studio keeps running fine. Plus, you do not need all of the plethora that Android Studio installs just for Xamarin.
Figure 1: Android SDK launcher.
The installation typically installs Android SDK level 19, 21, and 23 (23rd one can be selected from installation options). You should not just go ahead and start installing everything, even if someone asks you to. There is no point in doing that.
Figure 2: Android SDKs and tools provided.
Later in this post, I will show you which of the frameworks are required an necessary for your project to work and which of these are not at all required.
Installation of Android SDK
Another most important point to consider here is that on various locations online, you will find people saying that you should install SDKs from the minimum one required, all the way up to the latest one. No, that is not the solution and is not required at all.
For example, have a look here,
Figure 3: Android target platforms.
In this case, which SDKs do I need to install? If you said: All the way from 16 to 23, then you are wrong. The only SDK that is required and compulsory for you to have is the “Latest Platform”. Now, the concept of latest platform is a bit different. You cannot expect to have the latest Android version released by Google, and expect that to be the latest one in Xamarin also. Xamarin is not working under Google and their APIs come a bit later than Google’s APIs.
I have only installed the SDK platform for 25 and 23. I installed 25 because everybody was asking me to install everything. Which did not work in any case. So, what you need to do is you need to install only the Latest Platform, and any platform that you need to test your application on; in the case of emulators etc.
One more thing, the latest platform will differ as you will be working at the time of writing this post, it was Android 6.0 Marshmallow, whereas Nougat was released quite months ago, even then the latest platform in Xamarin was 6.0. And in Android Studio I was already targeting API level 25. Which means, that Android Studio API level and Xamarin level do not meet each other and thus you need to check again which of them are you going to support.
Emulators in Xamarin
Xamarin, if installed with Visual Studio, comes shipped with Visual Studio Emulator for Android. It requires you to have Hyper-V installed and active… Meaning, you can only access it on a Pro edition of Windows. In other editions, such as Home, you cannot run that. In that case you either have to fallback on Genymotion, or other products such as the Android emulator provided by Xamarin itself. The benefits of using these emulators are:
They come pre shipped and preconfigured.
All you need is a Pro edition of Windows (in case of Visual Studio’s emulator), or you need a commercial account; such as for Genymotion unlimited account.
However, my choice is a bit different. I consider using the same Android emulators that I used with Android Studio. There are various benefits to this,
You get the latest API levels before hand. My latest platform (as seen above) is Android 6.0, however, I get to run the application in Android 7.0 using the emulators by Android Studio. Fun eh?
You can use Intel HAXM, and it works even if you do not have a Pro edition of Windows. However, a CPU with virtualization technology is required — of course, an Intel CPU.
Visual Studio automatically detects the running Android device, and you can push your application to the running emulator and run it in super-fast mode.
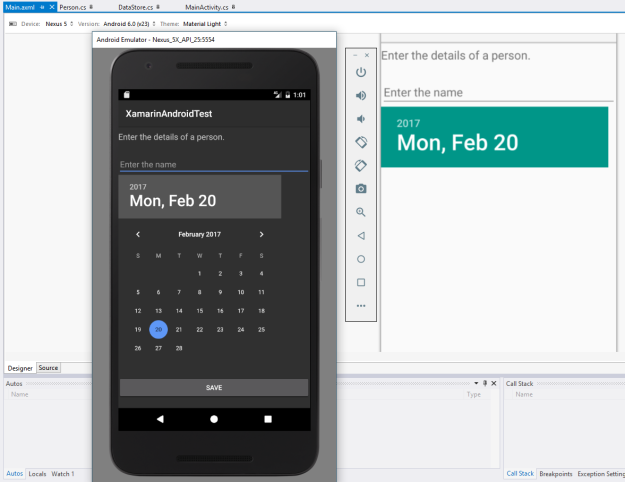
However, if you want to run your application on one of the Android Studio’s emulator, then you need to make only one thing sure: The platform level of the emulator and the platforms installed in Xamarin.Android SDK is similar. For example, if I have a device of Android 7.0, and I have not installed Android 7.0 as a platform level in Xamarin.Android SDK, then the application will not deploy; although it will build, it will try to deploy, but will not fail nor succeed. To overcome that, install the same SDK level in your Xamarin.Android as well as the Android Studio SDK. Then you can deploy your applications.
One thing and purpose of having Android 7.0 installed on Xamarin, was that I was testing my applications on Android Studio’s emulator, which had Android 7.0 installed, to have it accept the application, I needed to install Android 7.0 SDK on Xamarin as well. Otherwise, it won’t start debugging at all.
Figure 4: Android emulators shown in Android Studio AVD manager.
If you look close enough in the following, you will find a lot of easter eggs; Android 6.0 as target, yet running on Android 7.0 and so on.
Figure 5: Android Studio emulator with Android 7.0 running a Xamarin application targeting Android 6.0 application.
You will also see, that the Android emulator being used is the Android Studio’s emulator and not any other emulator and it runs and works just perfectly.
View not loading
Most of the times you will get an error message saying, Android SDK is outdated. Or to be specific, the error message is,
The installed Android SDK is too old. Version {API_LEVEL} or newer is required.
Then it provides you with a link to open Android SDK and install it. The problem here is that you are trying to target your build to a version, that is not installed at the moment. Such as, in my above example the target was Android 6.0 and the only SDK installed was 19 (the default one). That caused the problem for my setup to target the views to the latest API level.
In most posts, it is shown to actually either update the paths, install everything, or move the directories from one location to another, or even reinstall Xamarin.
The solution to this problem is pretty much straight-forward. All you need to do is:
Go to the Properties → Application.
Check for the “Compile using Android version:” value. Also note that the “Target Android version” can be selected as the “Use Compile using SDK version” to make things a bit more simple.
FInally, install the SDK for your target platform level.
One thing to note here, if your SDK shows that you have installed the platform however, you cannot run the application. Recheck the location of SDK being used.
Figure 6: Android SDK default paths in Visual Studio.
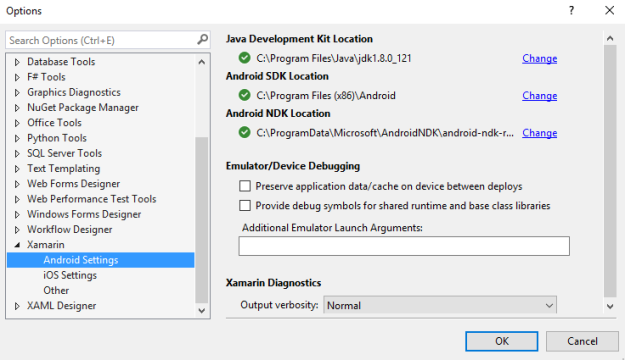
For that, go to Tools → Options → Xamarin → Android Settings.
Double check the Android SDK location property here. And make sure it is the location where your SDK is installed.
These will set up a few things in the system so that Xamarin works the way it should.
Java SDK required
In most cases, Java JDK 8 is recommended. By default you will be provided with JDK 7, and that works perfectly. But it is recommended to install JDK 8 and remove JDK 7. Reason?
JDK 7 is old. Really.
JDK 7 will cause your applications to target JDK 7, even if JDK 8 is installed because it overwrites the default JAVA_HOME variable. Since, JAVA_HOME variable needs to target JDK 8 location, there is no need to have JDK 7; since it will never be used.
Latest Android tools will be using and supported by JDK 8. Soon Xamarin will also require you to have JDK 8, because while compiling Xamarin to Android, it uses the Android libraries as well; SDK etc. They require JDK 8.
A simple step to do this would be, to remove the JDK 7 completely. Go to control panel for that. Next, set the JAVA_HOME environment to point to JDK 8 location. That will be different on devices, based on the build or versions. So, check it against your own system.
Final words
Xamarin itself is a very powerful tool provided by Microsoft. Plus, the benefits of Xamarin, especially Xamarin.Forms, outweigh any disadvantages of it. The main disadvantage of this is, the learning slope is really very slippery — not just steep. Most of the beginners leave out learning the Xamarin framework, because learning a simple language such as Java and having maximum code already provided is an easy way to have your work done. Whereas, in Xamarin you need to not just learn the tools but also to understand which plug goes to which socket.
I tried my best to provide you with a post that has the solutions to most widely faced problems. The problems talked about here, were all generic and not a specific case because I needed future readers to also get help from this post.
If you find any other error, do let me know by commenting and I will try to find a solution — a real solution — and then share it with you and the rest of the community. 🙂
For quite a while by now, I wasn’t doing any mobile development and I never considered myself to be a mobile developer either. Until a few days back when I realized that I should look into a few of the familiar and amazing stuff, such as database development, or writing database programs in Android. Working with the stuff on Android, I learnt a few basics about SQLite databases and how they actually work, plus I really enjoyed a huge performance they provide for the applications by providing the data in a very fast manner, yet maintaining resilience. That was not the most important part that I learnt in the previous weeks, the most important part I learnt was the use of Xamarin APIs for SQLite programming in Android. And, just personally saying, Xamarin provided even a better interface at programming the databases as compared to Java APIs for this task.
I don’t want you to have any background knowledge of SQLite, or whether you have previously worked in SQLite or Android database system or management. Because, in this post I will start by the basics and then build on top of them. Secondly. however I do want and expect you to have a basic understanding of Xamarin and C# programming language because we are going to heavily use C# programming for building Xamarin applications. So, I believe we should start by now.
Understanding database systems
In database theories, did you ever hear about words like, “database servers”? I am sure you did… The database servers are assigned a task to manage the data sources on a machine. They provide input/output channels to clients, or other processes to save or read the data from the data sources. It is the responsibility of the database server, or also known as database engine, to take care of the communication, data caching, data storage and data manipulation and it only returns the data as it is required and requested — nothing more, nothing less. But as we know, database engine is just a general terminology here. The actual product, will look something like, “MySQL”, “SQL Server”, “Oracle Database”, “mariaDB”, etc. All of these engines are installed on the machine, and then they allow the developers (or IT experts) to create the database on the machines, and only then can someone access data, or insert the data to the system. There were various reasons to use those engines,
They provided an abstracted means to manage the data — in other words, data layer was managed by them and the rest of the layers were programmed independent of managing internal and physical layers of storage.
They provided an easier way to manage the data. You just install the server, and you just execute commands to manipulate the data, or read the data. SQL language was developed for this.
You can have multiple customer devices, all of them connected to a central server to share and fetch the data.
Authentication problems were solved. Only one machine, or program needed to know the authentication, or the mechanisms to retrieve the data and how to store the data. Other machines were agnostic as per this information. However, you can always use tokens, or account systems to allow them to perform some administrative tasks.
But as the world progressed, there were changes to the way applications were developed. Software developers wanted to develop application software, that would run on the machines themselves and store the data locally; instead of having to build a large server processing and storing the data. The problem with older database systems was that they were installed at a location and a network connection was required to retrieve or store the data. If we skip out all of the problems of network based data instances, such as, security vulnerabilities etc, even then we are left out with other issues such as, what application will do when the network is down? Or what happens to all customers, if server goes down, or server is upgrading and many other similar issues.
In such cases, it was a good approach to have the server installed with the application. But the size was an issue, servers really contain a lot of services, task managers, data handlers, connection managers, authentication managers and so on and so forth. So in those cases, either the data was stored in the form of files, or structured data. That gave birth to embedded databases. The databases were embedded, in other words, they were just files and a script code to work with them. Every embedded database works in this way, they are just simple files containing the data and then there are APIs or libraries, or simple program scripts that are executed to fetch the data or write the data, and the script updates the data sources. The benefit is, that you can have this script installed with the application with no extra cost or dependency at all.
Thus, SQLite was brought into action
SQLite, as mentioned above, like all other embedded database systems, was written in C language as a script that managed the data sources. There were various benefits of having SQLite service instead of the large database servers on a remote machine.
It provided similar SQL language syntax for data manipulation and data extraction.
It can be used with every popular language nowadays. It has the library written in languages such as C++, Java, C#, Python and even Haskell for function programming.
There is an optional support for Unicode character sets as well. You can turn it off for ASCII coding, or map your own data.
It is a relational database model. Everything gets stored in a table.
There is support for triggers as well.
It is dynamically typed column typing system. Which means, it can be easily programmed with any data type you have, it will internally map the types to the ones you want and the ones that column is expecting; such as, converting the string data to integer when you pass “5”.
You can find it in most widely used operating systems too:
On mobile environments, Android is on the top.
On desktop: Windows 10 provided a built in support for this.
Since this is an embedded server, you can have it on anywhere.
So with these things and benefits in mind, Android also focused on providing the SQLite databases as their primary databases for applications. So in this article, we will look forward to understanding and then using the databases for our own benefit; storing the data and retrieving the user data when they need it in the application. Almost every application in Android uses this database provider, for its speed, and more-than-enough benefits.
Understanding SQLite system in Android
SQLite systems play an integral role in Android APIs for app development. The reason behind this is that SQLite were added to Android system ever since API 1.
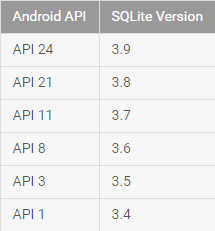
FIgure 1: Android API and SQLite API level.
This is the default database provided and supported natively in the API, and with every update in the Android API, an update for SQLite version is also provided, so that latest bug fixes and performance issues can be easily addressed with every updated.
Figure 2: Android and SQLite logo.
And even if you are building an application that provides data for other applications installed, either for your own organization, or for other vendors, you can use SQLite as the backend of your data layers.
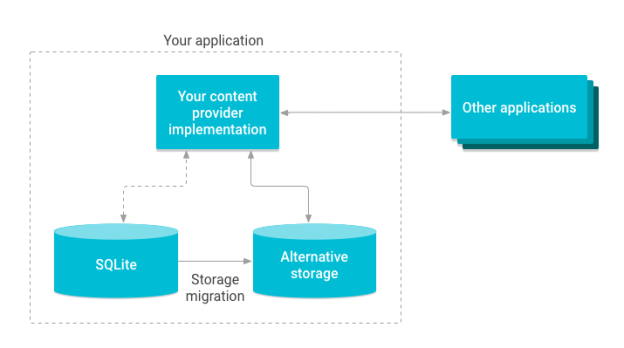
Figure 3: Content providers structure as captured from Content Providers documentation on Android Developer website.
In Android, it is just a matter of objects and their function that you can write to implement full feature data storage API and the models in your data. There might be support for some object-relational mappers out there, but I want to talk about the native libraries out there.
In Android API sets, the providers for SQLite library are available under, “android.database.sqlite” package. The most prominent types in the package are,
SQLiteOpenHelper: This is the main class that you need to inherit your classes from, in order to handle the database creation, opening or closing events. Even the events such as create new tables, or deleting the old tables and upgrading your databases to a latest version (such as upgrading the schema), are all handled here in this class-derived classes of yours.
SQLiteDatabase: This is the object that you get and use to either push the data to the database, or to read the data from the database.
SQLiteCursor: This is the cursor implementation for working with the data records that are returned after “Query” commands.
Their connection is very much simple, one depends on the other object and they all communicate in a stream to provide us with the services that we require of them.
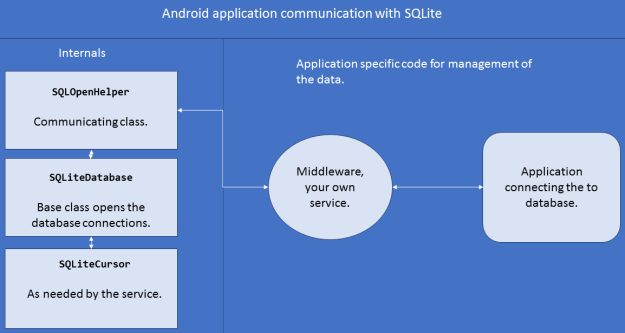
Figure 4: Structure of the system communication with SQLite database.
I hope the purpose of these is a bit clear as of now. The way they all communicate is that, your main class for the data manipulation first of all inherits from SQLiteOpenHelper to get the functions to handle, then later has a field of type SQLiteDatabase in it to execute the functions for writing or reading the data. The final object (SQLiteCursor) is only used when you are reading the data, in the cases of writing the data, or updating the data, that is not required. But in the cases where you need to fetch the data, this acts as a pivot point to read the data from the data sources. As we progress to program the APIs, you will understand how these work.
Wrapping up the basics
This wraps us the basics of SQLite with Android and now we can move onwards to actually write an application that lets us create a database, create tables for the data that we are going to write down to it, and then write the objects and their functions that we will use to actually store data in the tables — CRUD functions.
Writing the Xamarin application
Unlike my other posts, I do expect you to create the application because this is one simple task that, every post about Xamarin or any other Visual Studio based Android project will have in common so I will not waste any of my time on this. For a good overview and how-to, please go through this basic “Create an Android Project” post on Xamarin documentation website itself. It gives you a good overview and step-by-step introduction to creating a new project in either Visual Studio or Xamarin Studio, anyone that you are using as per your choice or need.
Background of our models and data storage
So, like every data layer developer we would first define our structure for the data to be saved in the databases. These are just simple classes, with the columns presented as a property of the object, and a type associated with it that makes sense. So we will first of all define that, and then we will move onward. The purpose is to make sure that we are both on the same track and level of understanding how our application should work and process the data.
In the form of class, our data structure would look like the following,
public class Person {
public int Id { get; set; }
public string Name { get; set; }
public DateTime Dob { get; set; }
}
Rest of the stuff is not important, and just to keep things a lot simple, I just added 3 columns — properties of the object. We will simply get these values and then show them to the users in a Toast message in the same activity, just to keep things a bit simple as of now. So now we need to create the database, tables and the columns inside the tables to represent our objects.
For that, it is my general approach to write the code in a different folder and name it generally; such as a “DataStore” file inside the “Services” folder, or “DbHelper” file inside the “Model” folder etc. These are a few good approaches that help you to write good codes in the applications. You are allowed to use any of these approached, I used the first one. The basic structure for the class is,
// Inheriting from the SQLiteOpenHelper
public class DataStore : SQLiteOpenHelper {
private string _DatabaseName = "mydatabase.db";
/*
* A default constructor is required, to call the base constructor.
* The base constructor, takes in the context and the database name; rest of the
* 2 parameters are not as much important to understand.
*/
public DataStore (Context context) : base (context, _DatabaseName, null, 1) {
}
// Default function to create the database.
public override void OnCreate(SQLiteDatabase db)
{
db.ExecSQL(PersonHelper.CreateQuery);
}
// Default function to upgrade the database.
public override void OnUpgrade(SQLiteDatabase db, int oldVersion, int newVersion)
{
db.ExecSQL(PersonHelper.DeleteQuery);
OnCreate(db);
}
}
This is the default syntax for your basic database handler, that handles everything about the database creation and deletion. One thing you might have noticed, I did not include “PersonHelper” object here. There are a few things I want to talk about this object, before sharing the code.
This is not the model itself. It is merely the helper we will use.
This class is the class-base representation of the table in our database. This class contains the query that will be executed to create the table, including any constraints to be set such as PRIMARY KEY etc.
It will help us to store the “Person” objects, retrieve the “List of Person” objects. Even update or delete them as well.
Let us have a look at the class itself,
public class PersonHelper
{
private const string TableName = "persontable";
private const string ColumnID = "id";
private const string ColumnName = "name";
private const string ColumnDob = "dob";
public const string CreateQuery = "CREATE TABLE " + TableName + " ( "
+ ColumnID + " INTEGER PRIMARY KEY,"
+ ColumnName + " TEXT,"
+ ColumnDob + " TEXT)";
public const string DeleteQuery = "DROP TABLE IF EXISTS " + TableName;
public PersonHelper()
{
}
public static void InsertPerson(Context context, Person person)
{
SQLiteDatabase db = new DataStore(context).WritableDatabase;
ContentValues contentValues = new ContentValues();
contentValues.Put(ColumnName, person.Name);
contentValues.Put(ColumnDob, person.Dob.ToString());
db.Insert(TableName, null, contentValues);
db.Close();
}
public static List<Person> GetPeople(Context context)
{
List<Person> people = new List<Person>();
SQLiteDatabase db = new DataStore(context).ReadableDatabase;
string[] columns = new string[] { ColumnID, ColumnName, ColumnDob };
using (ICursor cursor = db.Query(TableName, columns, null, null, null, null, null))
{
while (cursor.MoveToNext())
{
people.Add(new Person
{
Id = cursor.GetInt(cursor.GetColumnIndexOrThrow(ColumnID)),
Name = cursor.GetString(cursor.GetColumnIndexOrThrow(ColumnName)),
Dob = DateTime.Parse(cursor.GetString(cursor.GetColumnIndexOrThrow(ColumnDob)))
});
}
}
db.Close();
return people;
}
public static void UpdatePerson(Context context, Person person)
{
SQLiteDatabase db = new DataStore(context).WritableDatabase;
ContentValues contentValues = new ContentValues();
contentValues.Put(ColumnName, person.Name);
contentValues.Put(ColumnDob, person.Dob.ToString());
db.Update(TableName, contentValues, ColumnID + "=?", new string[] { person.Id.ToString() });
db.Close();
}
public static void DeletePerson(Context context, int id)
{
SQLiteDatabase db = new DataStore(context).WritableDatabase;
db.Delete(TableName, ColumnID + "=?", new string[] { id.ToString() });
db.Close();
}
}
This is a simple, yet very simple, CRUD-based-table-structure-class for our application. 🙂 We will be using this class for any of our internal purposes, of mapping the objects from the database to the code itself. The code itself is pretty much simple, the most important objects used in the code above are,
SQLiteDatabase
This is the database file, that we get from the helper object (our own DataStore object), one different primarily in Java and C# code is that C# code looks shorter — (yes, a personal line). For example, have a look below,
// C#
SQLiteDatabase db = new DataStore(context).WritableDatabase;
// Java
SQLiteDatabase db = new DataStore(context).getWritableDatabase();
To understand the difference, you should understand the encapsulation in Object-oriented programming languages and properties in C#. To an extent that does not make any difference, but if you come from Java background and start programming Xamarin, you will require to understand the best of both worlds and then implement them in your own areas.
Heads up: Entity Framework Core can be used as well in Xamarin applications. Thanks to .NET Core.
ContentValues
In Android APIs, this was the wrapper used to wrap the column values for each of the insert, or update for the records. The same object is provided here and you can add the values here, that SQLite engine would use and push the values to the database.
ICursor
The basic cursor object, used to iterate over the collection. In Android API using Java, you can get the following code,
// Java
Cursor cursor = db.query(...);
And in the C# code, you get a bit different version, but that does not matter at all as you can always implement the ICursor object and create your own handlers for the data. That helps in many ways,
You get the validate the data before generating the list itself.
You can build your own data structures and load them in one go.
You can use and implement other services as well and then consume them as well in the same cursor object — but in many cases, this is not required at all.
Create and Delete queries
If you pay attention to the initials of the helper class, you will find that there are constant string values. Those are used to create and delete the tables. For their usage, please see the OnCreate and OnUpdate functions in the DataStore class above.
One more thing, in SQLite when you create a record that is assigned, “INTEGER PRIMARY KEY“, that column automatically starts to point at the ROWID, that is the similar to AUTO INCREMENT in most database systems. That is why, we don’t need to manage anything else and SQLite itself will make sure that our records are all unique by incrementing the row id. Of course there are a few problems with this as well, because the value doesn’t guarantee to always “increment“, but it guarantees to “be unique“.
Building the UI
On final step in this application would be actually create the UI of the application’s main activity. What I came up with, for this simple application was the following interface. I hope no one is offended. 😀
Figure 5: Interface Design in Xamarin, in Visual Studio 2015.
A few configuration on the top left corner may also help you to understand and build the similar interface if you want to have the similar interface in your own application as well.
So, now we are ready to run and test our application in the emulator.
Running the Application in Emulator
At this point, we may walk away on our own paths because I personally like to use the native Android SDK emulators, instead of the Xamarin’s Android emulator or Visual Studio’s Emulator for Android. There are many reasons for this choice of mine, and I will share that in a later post sometime.
But for now, you can run the application in any of your own favorite emulator, even on your own mobile device.
Figure 6: Application running in emulator.
I have already filled the UI with the required information, and now I will be writing the backend code — because I am that awesome.
protected override void OnCreate(Bundle bundle)
{
base.OnCreate(bundle);
// Set our view from the "main" layout resource
SetContentView(Resource.Layout.Main);
// I removed the default one, and added my own.
Button button = FindViewById<Button>(Resource.Id.button1);
button.Click += Button_Click;
}
private void Button_Click(object sender, EventArgs e)
{
EditText nameField = FindViewById<EditText>(Resource.Id.name);
DatePicker picker = (DatePicker)FindViewById(Resource.Id.datePicker1);
string nameStr = nameField.Text;
DateTime dob = picker.DateTime;
if (string.IsNullOrEmpty(nameStr))
{
Toast.MakeText(this, "Name should not be empty.", ToastLength.Short).Show();
return;
}
// Just save it.
Person person = new Person
{
Name = nameStr,
Dob = dob
};
DataStore.PersonHelper.InsertPerson(this, person);
Toast.MakeText(this, "Person created, fetching the data back.", ToastLength.Short).Show();
var people = DataStore.PersonHelper.GetPeople(this);
person = people[people.Count - 1];
Toast.MakeText(this, $"{person.Name} was born on {person.Dob.ToString("MMMM dd yyyy")}. \n {people.Count} people found.", ToastLength.Short).Show();
}
The outputs, after having this code applied to the UI was the following,
Figure 7: Person created toast message.
Figure 8: Person details shown on the screen using Toast.
And, it works perfectly just the way we expect it to. You may have noticed that we convert the Date object to the standard string object, and then we parse that same string back to the Date object. Then using SImpleDateFormat we format the data properly.
Final words
Finally, in this post we tackled the problem of SQLite databases in Android using Xamarin APIs. The process itself is pretty much simple and straight-forward, and you don’t need to go through a lot of pain. Just remember these three steps:
Inherit your main data layer class from SQLiteOpenHelper.
Handle the OnCreate and OnUpgrade (and other) functions to create the tables.
Write the CRUDs and you are done.
Also, remember that you should execute the Delete function on the database object, because writing a native SQL query will have a few problems.
DELETE query does not release the underlying storage space — nor does Delete function.
Your new items would anyways come up in the free space, but that free space will not be released to operating system for other data and stuff.
To release the space, you will need to execute VACUUM command. It repackages the database file, with taking only the space it needs.
However, Delete function will help you to overcome SQL Injection problems by passing the parameterized queries. Food for thought: Can you figure out the parameter in the queries above?
While I was working on cloud computing, and other similar technologies, I somehow stumbled upon this new thing that I did not have heard of before (quite a few weeks from now) and I found it really interesting to watch about with and to learn and to share my own understanding of this technology with you guys. I will try my best to keep the main idea as simple as possible, but explain everything from A to Z in a much easy way, that it will look as if the concept was always in your mind.
So, let us begin with the first initials about the serverless computing and how it all began.
How, it all began…
If you guys have been into the IT and programming geekiness for the past few years, you must have witnessed how things changed, from physical machines to virtualization, to containers and all the way to, what we now call serverless computing. Whether this new tech trend comes down the stream as I mentioned, or perhaps someone else knows better as how this all began is not the question or the topic of concern, the main thing is that we now have this another topic to cover before we actually start up and design the applications. You will see, in this post, how one way of deploying application has pros and cons, and how serverless comes up to solve the problems — or ruin everything at all. There are some pros to serverless computing, and there are obviously a lot of cons to serverless computing.
The buzz word of serverless computing didn’t take much longer, because we now have Internet and one new thing from the west, reaches east in no time at all. The question to ask is, “Do we understand what they wanted us to?” And this is the question that I am going to address in this post of mine, so that all of us really understand the purpose, need and reason of serverless computing today.
I am going to use Azure Functions, to explain the usage, benefit and “should I” of the serverless computing. The reason I chose Azure was that everyone was already covering a lot of Amazing Lambda stuff, so I didn’t want to do use that, also I am working on Azure a lot so I thought this is it.
Understanding the term, “serverless”
Primary focus of our is to explain the term, “serverless”, Azure usage would just be to give you an overview of how that actually works in real world.
Figure 1: A simple yet clear difference in traditional vs serverless approach toward server management.
The picture above, was captured from this blog, and it provides a very good intuition towards the difference in what we use, and what serverless offers. But this does not mean that the image above provides a 100% true and only difference in the both worlds, sometimes the differences boils down to zero; such as in the cases, where you are going to use architectures such as cloud offerings. In such scenarios, the total difference in the cost is how you selected the subscription. As we progress in the post, I will also draw a margin line in many other aspects of this methodology. Keep reading.
Just like the term cloud computing was mistaken for various reasons, and for various acts, the term of serverless is also being mistakenly understood as a platform, where servers are no longer needed. As for cloud computing, you might want to see, Cloud Computing explained by Former IT Commissioner, and try to consider the fact that we are in no way understanding the technology the way it is meant to be understood. The same is the result for serverless, when I tried to search for it on Google, I even saw computer devices being dumped into the dustbin; which triggered me, that people are so not understanding the term itself. For example, go here, Building a Serverless API and Deployment Pipeline: Part 1 and try to just see the first image and please remember to come back as soon as possible. You will get my point. Finally, I mean no offence to anyone being mentioned in this paragraph, if you are the target in either one of the link, kindly get a good book or contact me I will love to teach you some computer science.
Figure 2: Just in the case that blog post is not accessible or the author takes the image down, I just want to show you the image. Still, no offence please.
So what exactly is serverless computing? The basic idea behind this, is to remove the complexity or the time taken to manage the servers, not the servers themselves. In this scenario, we actually use a framework, platform or infrastructure, where everything, even the booting, executing and terminating of our application is managed by the provider itself. Our duty, only is to write the code and the magic is based on the recipe of provider. Just to provide you with a simple definition of serverless computing, let me state,
Serverless computing is a paradigm of computing environment in which a platform or infrastructure provider manages booting, scheduling, connection, execution, termination and response of the programs without needing the development teams to manage the control panel.
Few, that wasn’t so tough, was it? Rest of the stuff, such as pricing models, languages or runtimes provided, continuous deployment or DevOps is just a bunch of extra topping that every provider will differ in the offerings. That is one of the reasons, I did not include any statement consisting of anything about the pricing models, or the languages to use — whereas in this post, I will use C#… I am expecting to write another post that will cover Python or other similar interpreted languages.
Benefits of Serverless architecture
If you migrate your current procedures, and communicators, to serverless paradigm you can easily enjoy a lot of benefits, such as cost reduction, freedom from having operations team to manage a full fledge server and much more. But on the same time, I also want to enlist a few of the disadvantages of serverless computing, at the end of this section.
Cost model
Ok let me talk about the most interesting question in the mind of everybody perhaps. How is this going to change the way I am charged? Well, the answer is very much relative to what you are building, on what platform you are building and how much customers do you have, plus how they interact with your application. So, in other words, there is no way we can judge the amount of charges you are going to play with this. In the following sections, I will give you an overview of another special part in serverless programming, that you can use to consider the pricing model for your application.
NoOps
Do not be mad at me for adding a new term in the computer science; if it has not yet been added there. Now let me get to the point where I can explain the concept of resolving the teams, such as development, operations etc. and then getting to a point, where you can enroll “serverless” to the environment. In modern day computing, we have, let’s say, implemented DevOps and we need to have a mindset where our teams are working together to bring the product to market for users. A DevOps typically has the following tasks to be conducted,
Planning and startup, user stories or whatever it is being called.
Source control or version control
Development; any IDE, any language
Testing; there are various tests, unit testing, load testing, integration testing etc.
Building; DevOps support and encourage continuous integration
Release; same, continuous deployment is recommended
From this, you can see that the developers only need to work in a few areas, Planning, Development and Building. Version control systems should be managed by the IDE and timers should be set to them to control when the versions or updates are checked in each day, updated versions must be released into the market by operations teams etc. However, since now in the field of serverless, we do not have to “release the software” to market, and we also do not need to manage any sort of underlying server if our application is web based, thus we can somehow remove the operations team, or include them in the development team as application developer team. I read a research guide a few days ago naming DevOps – Ops as AppOps, but however I would like the term of NoOps, because the considerations of them being simple operations team is removed and they now work with the application development team, focusing entirely on the code, and the performance or uptime of the application, instead of the servers or virtual machines.
So, let’s count the purpose of NoOps in this field,
Planning and startup
Source control or version control
Development
Testing; I can strikethrough this one as well.
Building
Release
Clear enough, I believe. Before we get into another discussion, let me tell you why I think these are the way they are; why did I cut a few in the list.
Planning and Startup
First of all, planning and startup in this does not make any sense at all. Please see below, the section in which I am talking about the “whens” to select serverless architecture, that section will depict when you should use serverless approach over the current “modern” approaches. Once you have gone through that, you will understand, that in serverless arch, the planning is done beforehand.
Thus, there is no need to again sit around, and have the kanban board messy once again. If you are going to work on that board again, please go back and work in DevOps environment, serverless is not for you. As mentioned below, serverless is for the programs that do not run for 4-7 hours, but just for an instance, each time they are called and they are entirely managed by the infrastructure provider.
Version control
Since this is directly targeted towards the development, or the core portion of your application, this is a part of serverless architecture design. Almost every serverless platform that I have seen as of now, uses version control services or provides best practices of DevOps; I know. Azure Functions provide you with features that you can use to update the source code of your function, Amazon Web Services’ Lambas allow you to use GitHub, same goes to almost all; have a look at Google’s microservices service, they support GitHub based deployment of Node.js applications and then manage how to run them.
In the cycle of development of a serverless application, this can come as the first step after every first cycle.
Development
Yes, although we removed the servers and other IT stuff from the scene, we still need developers to write up the logic behind the application.
Testing
The reason that I left this option active in the current scenario was, that if you are using version control and then you are deploying the application’s code to the server, my own recommendation and DevOps also, would be to test the code before going to the next step, as it might break something up ahead.
In serverless arch, we are allowed to use source controls, so, before forwarding the code from there to the server, why shouldn’t you run some tests? In serverless arch, we don’t have to worry about the servers, but sure we do need to worry whether the code ran, or did it just break all the time?
In a serverless architecture, we do not technically build a full fledge, or full featured application that takes care of everything, instead we simply write a “if this then that” sort of application. If you understand the concept of “Internet of Things”, then you can think of a serverless application as the the hub that manages the communication and responds to an event; message; request. In such cases, it is not required to implement every test possible, instead, we can perform simple tests to ensure that the code does not break at the arrival of request, and at the dispatch of a response. These are just a few, top of my dumb piece assumptions and suggestions, based on what your serverless application does, you might need other tests, such as pattern matching or regular expressions to be tested against.
I repeat, this is the most important part of serverless programming. I cannot put more effort in saying this, but you get my point, if you are a team and you are going toward the serverless paradigm to lift the response rate, then you first of all need to ensure that the program will be resilient to any input provided to it and will not break at all. Even if there are some issues, how does the program respond to those errors?
Building
I removed that step, but I could have also left that as it was. There are reasons for this, because, the infrastructure may provide you with support to publish built programs. We are going to look into Azure Functions, and Azure supports publishing built programs that execute, instead of scripts that are to be interpreted each time that function has to execute.
But in many cases, you do not need to take care of, or even worry about the build process, since the functions are small programs and they don’t require much of the stuff that typical applications require. You can easily publish the code, and it will execute in a moment. Serverless providers allow interpreted languages to be used as the scripts too, such as Batch files, you can also use Python scripts, or PHP files. But again, every provider has their own specification for this, Azure Functions support any kind of program that you can write, or build, you can upload it on the server and they will host it and your users can connect to it next time they send a request, or interact with the application; mobile, web or any other IoT based device.
Release
Submitting the code out to the version control, was the only release we are going to worry about.
Winding up the basics
Although what I covered, just scratched the basics about the serverless architecture, and there is a lot more to it, than just this singular concept of what to do, and what to leave out. But going any deeper into the rabbit hole might be confusing and might get us off-track as per this post’s structure. So I will not go down, but just for winding us the basics, let us go through a few things.
Do not consider the serverless architecture as a replacement for your current physics servers or container based environments. Serverless are just used to take the events and then trigger another server or virtual machine to act on that event, with the provided data. Nothing else.
Before going serverless, you and your team must understand one fact: “It is your duty, to test the code, and the validity of your code, and it is the duty of your platform provider, to ensure that the code runs the way it is intended to be run on the runtime intended.”
Pay a lot of attention to testing, testing, testing. I repeat, other than development if there is something that needs to be done, it is testing.
The payment plan, in many cases differ from one and other. Sometimes you might choose a monthly plan, sometimes if your users are not in thousands, then you can select the plan where you only pay for the time your function is executing; only for resources used.
Microsoft Azure Functions provide full support for various languages and runtimes, you can use C#, then you can as well choose JavaScript, there are other methods of writing the function code, such as using Python and PowerShell. You can also upload the compiled code and then run it. In other words, if it can execute, it can be a function.
One final thing, a function is only a program or handler, that runs for a small time (10ms-1.5s), if it takes more than that, then it will raise other errors and you would face other problems as well. Always keep the function code short, and as soon as possible terminate it by triggering other services or passing the data on to other service handlers, such as you can trigger the function from an IoT hub and then use other services such as SMS or SMTP services to send notifications and before sending notifications close the function, by only triggering those services and passing the data.
In many ways, this architecture can help you out. But if used badly, it would be like shooting in your own feet. In my own experience, I have found that the architecture can create a lot of problems for you as well, and it might not always be as much helpful as you think. So, use wisely.
Azure Function example
I didn’t want to write a complete guide on serverless architecture, because I might have other posts coming out on this one as well, so let us go a bit deeper and have a look at the Azure Functions feature and see how we can write minimal serverless functions in Azure itself.
So in this example, I am only going to show you a bit of the example that can be used to show you how functions work, in future posts I might cover the HTTP bindings to the functions, or other stuff such as DevOps practices, but for this post let me keep it really short and simple and cover the basics.
Basic function file hierarchy
At the minimum, a function requires an executable script (in any runtime), and a configuration file that specifies the input/output binding of the function, timers or other parameters that can be used for the proper execution. That function.json file controls the execution of the function, it takes all the configuration settings, such as the accounts or services to communicate with. So for instance, in a simple timer based function the following files are enough to control the function itself,
The code in both the files is as the following one,
using System;
public static void Run(TimerInfo myTimer, TraceWriter log)
{
log.Info($"C# Timer trigger function executed at: {DateTime.Now}");
}
The JSON configuration file has the following content,
What their purpose is, let me clarify the bit about it in this post before moving any further.
Note: In another post, I will clarify the meaning and use of function.json file, and what attributes it holds. For now, please bear with me.
An executable script
The executable script can be C#, JavaScript or F# or any other executable that can run. You can use Python scripts as well as a compiled executable script.
Configuration file
The function.json file has the settings for your function. The above provided code was a very basic one, the complex functions would have more bindings in them, they will have more parameters and connection names or authentication modules, but you get the point.
In the file, the name and direction of the binding is compulsory. However, other settings are based entirely on the type of binding being used. For example, HTTP triggers will have different settings, timer triggers will require different settings and so on and so forth.
Executing
Azure provides the runtime for almost every executable platform, from PowerShell, to Python, to JavaScript, to C# scripts (the above provided code is from a C# script file) and all the way to other scripts, such as batch etc. Runtime also supports native executables — and this part I yet have to explore a bit more to explain which languages are supported in this scenario.
I will not go into the depths of this concept, so I will leave it here, anyways the output of this function is as,
2017-02-03T17:35:00.007 Function started (Id=3a3dfa76-7aad-4525-ab00-60c05b5a5404)
2017-02-03T17:35:00.007 C# Timer trigger function executed at: 2/3/2017 5:35:00 PM
2017-02-03T17:35:00.007 Function completed (Success, Id=3a3dfa76-7aad-4525-ab00-60c05b5a5404)
2017-02-03T17:40:00.021 Function started (Id=a32b986c-712e-4f30-84c9-7411e63b5356)
2017-02-03T17:40:00.021 C# Timer trigger function executed at: 2/3/2017 5:40:00 PM
2017-02-03T17:40:00.021 Function completed (Success, Id=a32b986c-712e-4f30-84c9-7411e63b5356)
2017-02-03T17:45:00.009 Function started (Id=c18c0eef-271d-4918-8055-64e3f31f953a)
2017-02-03T17:45:00.009 C# Timer trigger function executed at: 2/3/2017 5:45:00 PM
2017-02-03T17:45:00.009 Function completed (Success, Id=c18c0eef-271d-4918-8055-64e3f31f953a)
2017-02-04T10:27:54 No new trace in the past 1 min(s).
The timer trigger keeps running and keep logging the new events, and process information. You will also consider, that this is the same output that Node.js or F# programs would give you, the only difference in these 3 (only 3 at the moment), is that their runtimes are different, the binding and input/output of the functions is managed entirely by Azure Functions itself and developers do not need to manage or take care of anything at all.
Wrapup
Since this was an introductory post on serverless programming and how Azure Functions can be used in this practice, I did not go much deeper in the explanation of the procedures of writing function applications. But the post was enough to give you an understanding of the serverless architecture, what it means to be serverless and how DevOps transition to NoOps. In the following posts about serverless, I will walk you around writing the serverless applications and then consuming them from client devices; Android or native HTTP requests.
Finally, just a few things to consider:
If your functions take a lot of time to execute, such as 1 minute, or even 30 seconds, then consider running the application in a virtual machine or App Service. A function should be like a handshake negotiator, it should take the data and pass the data to a processor, itself it must not be involved in processing and generation of results.
Your functions should be heavily tested against. I am really enforcing a huge amount of tension on this one, as this point needs to be taken care of. Your functions are like the welcomers, who warmly welcome the incoming guests to your servers. If they fail in doing so, the data may never come back (data being your users; events, or anything similar).
Functions follow the functional programming concepts more, so, in functional programming the functions are not stateful. They are stateless, meaning they do not process the data based on any machine state, attribute, property or the time at which they are executed. Such as, a function add, when passed with a data input of “1, 2, 3, 4, 5”, will always return “15”, since the process only depends on the input list.
As we start to develop our own serverless APIs and applications, we will also look forward to further more ways that we can develop the applications, and write the application code in a way that it does not affect the overall performance of our service.
Nonetheless, even if not being implemented in the production environment, serverless is a really interesting topic to understand and learn from a developer’s perspective as you are the one taking care of everything and there are no cables involved. 😉
SQL Server has been released for Linux environments too, and after ASP.NET we can now use SQL Server to actually workout our servers on Linux using Microsoft technologies without having to purchase the licenses and pay a fortune. But that is not the case, at least for a while… Why? I will walk you through these critical aspects of the SQL Server and Linux continuum in this post, I am really looking forward to exploring a lot of things right here with you, by reading this post, you will be able to go through many areas of SQL Server on Linux and see if you really need to try it out at the moment or if you need to wait a while before diving any deeper in the platform.
I personally enjoy trying new things out… There are many out there who just try things out, I F… no, no, I dissect things up to share the in-depths of what everything has, what everything says and really is and finally, should you consider it or not. That is the most important part. After all, it is you, who is the main focus of my attention I want to tell you, share with you, what I find. Thus, by reading my post, you will get idea about many things — SQL Server is in its initial versions on Linux so, this post is primarily a feedback, overview of SQL Server and not a rant on the product in anyway.
SQL Server 2016 available on Linux
Now starts the fun part, I believe almost all of you are aware of the fact that SQL Server 2016 is available on Linux after serving Windows only since a great time, plus .NET Core is available on Linux too, and if you have been reading my past articles and blogs you are aware of fact that I am a huge fan of .NET Core framework and how it helps Microsoft to ship their products to other platforms too.
Figure 1: SQL Server “heart” Linux. No pun intended.
Of course the benefit is for Linux users and developers because they now have more options, whether they like SQL Server or not is a different thing in itself. I personally enjoy the tools, such as SQL Server Management Studio, which is a free software to manage databases using SQL Server. The tool can be used for most of the database engines, however Microsoft only engines.
There are many posts that give a good overview and introduction to SQL Server on Linux, and I am not going to dive deeper into them… As I have an exam of Database Systems tomorrow. So, help yourself with a few of,
Without further delay, let us go on to the installation of SQL Server on Linux section, and see how we can get our hands on those binaries.
Installation of SQL Server engine
SQL Server, like on Windows, comes separately from tools. You have to install SQL Server and then you later install the tools required to connect to the engine itself — Note: If you can use .NET Core application, then chances are that you do not even need the SQL Server Tools for Linux at the moment. You can just straight away execute the commands in the terminal, I will show you how… And in my experience I found this method really agile and as per demand.
So, fire up your machines and add the keys for packages that you are going to access, download and install.
You will be prompted to enter “y” and press “Enter” key to continue the installation. This process will download and install the binaries in your system. It downloads the files and scripts that will later on set up the system for your instance, Once the setup finishes, you may execute the following script to start “installation” of SQL Server 2016 on your machine.
Figure 3: SQL Server installed on Ubuntu.
$ sudo /opt/mssql/bin/sqlservr-setup
Authenticate this script, as it requires a lot of permissions in order to generate the server’s engine on your machine. The default hierarchy is like this,
Figure 4: Files in the installation directory, ready to install engine.
You can see the setup script in the list, execute it in the terminal and it will guide you through setup.
Figure 5: SQL Server installer requesting user password during installation.
You will accept the terms, enter password etc. and server will be installed. Simple as that. But yeah, do remember the password you need it later to connect — there is no Trusted_Connection property available in this one.
You can also test the service to see if that is running properly, or running at all by going down to your task manager and looking for the running services. First of all, you can execute the following command to see if the server is running,
$ systemctl status mssql-server
Figure 6: The screenshot shows that the response has everything required to see whether service is running or not.
In most operating systems you can find the same under processes too,
Figure 7: SQL Server collects telemetry information; the last process tells this.
Once everything is working we can move onwards to download and install tools.
Installing SQL Server 2016 Tools
On Linux, the choice you have is very small and selected. You may download and install a few helpers and tools if you would like, such as “sqlcmd” program. Just giving a short overview of the steps required to install this package and to use it for some tinkering.
The procedure is similar to what we had, add keys, install the server,
The installation won’t take longer and you will be able to get the packages that you can later use, I won’t be showing these off a lot.
$ sqlcmd -S localhost -U sa
Do not enter password in the terminal at all, let the program itself ask for the password and user will enter it later, secondly user input will not be shown on the screen.
Figure 8: Result of SQL query in sqlcmd program.
This is enough and I don’t want to talk any more about this tool, plus I do not recommend this at all, why? See the result of SQL query below,
> SELECT serverproperty('edition')
> GO
Figure 9: Result of an SQL query, totally unstructured.
The results are not properly structured so they are confusing, plus you have to scroll up and down a bit to see them properly. So, what to do then? Instead of using this I am going to teach you how to write your own programs… I already did so, and I thought I should again for .NET Core.
Writing SQL Server connector app in .NET Core
I am going to use .NET Core for this application development part, it is indeed my favorite platform there is. On the .NET world, I wrote the same article using .NET framework, you can read that article here, How to connect SQL Database to your C# program, beginner’s tutorial. That tutorial is a complete guide to SQL Server, targeted at any beginner in the platform field. However in this, I am not going to explain the basics but I am just going to show you how to write the application and how to get the output.
Note: You should read that article for more explanations, I am not going to explain this in depth. I will not be explaining System.Data.SqlClient either, it is available in that post I referred to.
You will start off by creating a new project, restoring it, and finally open it up in Visual Studio Code.
$ dotnet new
$ dotnet restore
$ code .
I ignored the new directory creation process, thinking you guys know it yourself. If you have no idea, consider reading a few of my previous posts for more on this topic, such as, A quick startup using .NET Core on Linux.
After that, add a new file to your project, name it SqlHelper, add a class with same name in it,
using System;
using System.Data.SqlClient;
namespace ConsoleApplication
{
class SqlHelper
{
private SqlConnection _conn = null;
public SqlHelper()
{
_conn = new SqlConnection("server=localhost;user id=sa;password=<password>");
_conn.Open();
Console.WriteLine("Connected to server.");
}
}
}
You still require a simple SQL connection string for your database engine, there is a website that you can use to get your connection strings. I initially told you there is no version of using trusted_connection here because there are no Windows accounts here that we can utilize. Now, call this object from your main class and you will see the result.
using System;
namespace ConsoleApplication
{
public class Program
{
public static void Main(string[] args)
{
new SqlHelper();
}
}
}
Figure 10: Connected to the server.
The results are promising as they show we can connect to the server here. Now we can move onwards to actually create something useful. Let us just try to execute the commands (that we executed above) in our newly developed system, update the code to start accepting requests of SQL commands.
using System;
using System.Data.SqlClient;
namespace ConsoleApplication
{
class SqlHelper
{
private SqlConnection _conn = null;
public SqlHelper()
{
_conn = new SqlConnection("server = localhost; user id = sa; password = <password>");
_conn.Open();
Console.WriteLine("Connected to server.");
_execute();
}
private void _execute()
{
if (_conn != null )
{
Console.BackgroundColor = ConsoleColor.Red;
Console.ForegroundColor = ConsoleColor.White;
Console.Write("Note:");
Console.BackgroundColor = ConsoleColor.Black;
Console.ForegroundColor = ConsoleColor.Gray;
Console.WriteLine(" You may enter single line queries only.");
while(true)
{
Console.Write("SQL> ");
string query = Console.ReadLine();
using (var command = new SqlCommand(query, _conn))
{
try {
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
Console.WriteLine(reader.GetString(0));
}
}
} catch (Exception error) {
Console.WriteLine(error.Message);
}
}
}
}
}
}
}
This will start executing and will request the user to enter SQL commands, you can see how this works below,
Figure 11: Connecting and executing SQL queries on SQL Server.
So, you have seen that even a simple .NET Core program to write and manage the queries is way better are structuring the sqlcmd program on Linux. You can update this as per needed.
Tips, tricks and considerations…
In this section I will talk about a few of the major concepts that you must know and understand before diving any deeper in SQL Server on Linux at all, if you don’t know these, then chances are you don’t know SQL Server too. So, pay attention.
1. Default Directory?
There are so many articles out there already, yet no one seems to be interested in telling the world where the server gets installed. Where to find the files? How to locate database logs etc?
In Linux, the default directory is, “/var/opt/mssql/<locked out>“. You need to have admin privileges to access and read the content of this directory. So, I got them and entered the directory.
$ sudo dolphin /var/opt/mssql/
“dolphin” is the file manager program in KDE, sorry the display was not so much clear so I selected everything for you too what is inside.
Figure 12: Data in the “data” directory under “mssql” directory.
You can surf the rest of the directory on your own, I thought I should let you know where things actually reside. On your system, in future, it might change. But, until then, enjoy. 😉
2. Edition Installed
On Windows, you are typically asked for edition that you need to install on your machine. On Linux that was not the case and it installed one for us. The default one (and at the moment, only possible one) is SQL Server Developer edition. This edition is free of cost, and it has everything that Enterprise edition has.
To confirm, just execute,
SELECT serverproperty('edition')
Or, have a look above in figure 9 or 11, you can see the edition shown. All of recent products of Microsoft based on .NET Core are x64 only. ARM and x86 are left for future, for now.
3. Usage Permissions
Yes, you can feel free to download, use and try this product out, but remember you cannot use it in production or with production data. This is the only difference in Enterprise and Developer edition of SQL Server 2016.
Figure 13: No production rights are available in Developer edition.
Thus you should not consider this to be used with production data. You can, until a time when it is allowed, you should stick with Windows platform and download Express edition. It has more than enough space for small projects.
4. Should you use it?
Finally, if you are a learner like me, if you want to try something new out, then yes of course go ahead and try it out. You can install a Ubuntu on a VirtualBox to try this thing out if you’d like.
If you find something new, message me and we can chat on that. 🙂
On operating systems such as Microsoft Windows, and using great tools like Visual Studio, it is greatly easy to upload and publish your web application projects to Microsoft Azure but what about other platforms such as Linux? Microsoft has recently released PowerShell as open source project and that is a great tool to be used in the cases where you have developers who understand and can use PowerShell but if you don’t happen to have any, then you would require to use traditional tools and sometimes they will require you to manually perform these changes. In this post, I am going to cover the teams who are using Git repositories for their projects and I am going to cover how they can basically automate the publishing of their projects after each successful build. On Linux, we can basically create small scripts that run on the background just like PowerShell or the Windows command prompt terminal’s batch files. Git programs are required for this to run, actually what I am going to show in this is to execute the same commands but in a manner that most of the repository’s information is already built, the commit message is updated and the content is published to the Azure app service. The purpose of this guide is to make the entire process as easy to be understood, as A, B and C. I will be using a real world application to show you how to do what and where instead of talking generally about many things at the same time.
Before moving onward, a very little knowledge of how Git system works is required from you because some things might get a bit technical in the post below and thus you must have the know-how of how Git systems work in order to control the versioning of files.
Figure 1: Git logo.
Secondly, you are required to know how you can use “dotnet” script to create, build and run the .NET Core applications. If you don’t know .NET Core, I will reference to a few of my own articles that are beginner-friendly which you can read to learn more on this.
Finally, you are required to have an active Azure account with a working subscription. If you don’t happen to have on, you can get a free account with $200 credits to try out all of Azure! Once these are met, you can continue to actually using the article for something useful.
Creating the application — entire part
This part has been shared and taught many times, on many occasions. I wrote an article on the same concept, a few days ago and I would like to refer that article to you to learn how you can create a new application with web template in .NET Core. Creating and hosting ASP.NET Core application on Linux — Nothing Third-Party, read this article for a complete overview and a walkthough for the concept of building and running the applications on Linux environment. I will move onward from this step, because you must be aware of the ways of creating your own applications.
Deployment of web application to Azure
Now comes the main part, this article entirely focusses on the deployment of applications to Microsoft Azure instead of developing an application. There would be some parts, where I will be modifying the parts, but that is just to tell you how easy it would be to redeploy the application using the automation by executing a simple command. Although it is not required but you are required to have a very basic introduction to automation tools. You can get a good tutorial about these toolings easily from any software engineering guide.
Using git for deployment
Microsoft Azure uses many methods and ways to deploy the applications on the cloud, such as using Visual Studio to deploy the applications and leave the configurations to the tool itself. However, since Linux environments don’t have Visual Studio, most of the tasks are left with source control tools (Visual Studio Code also uses the same git programs to upload the code to repositories). I will show you, how you can create a minimal script or a program, that manages all of these tasks for you — automation program.
On Linux, mostly and typically, git comes pre installed in most of the Linux-distributions, such as Ubuntu, etc. However, if that is not available you get easily install it using
$ sudo apt-get install git
Or using a similar command, such as using yum etc. This would install and setup git for your environment. Once you have git installed, you need to set a few things up. Git requires the name, email address for notifying who made a change to the system. So for that we would require to execute the following commands,
You should pass the name and address values that you hold — I used Eminem and a random email address. And to check if your personal configurations are done correctly, you can execute the following command to test that,
$ git config --list
These are the required configurations that you must do before you can use git for any purpose at all.
Note: You also need to create a new web application service (Azure App Service) on Microsoft Azure so that you can deploy the application somewhere. Since I do not want to go deep into the development and starting of this session, I would like you guys to go and watch this video of mine, providing an overview of Microsoft Azure App Service (you may have to put the volume a bit higher).
Once you have that, you can continue onwards and actually set up repositories to deploy the application. I used the following information while creating a new service, so that if I use a name, you should know where did that come from.
Figure 2: Creating a new App Service.
Figure 3: Reviewing the information of App Service in Microsoft Azure.
Upon creating, you can visit the web service from your browser using the link provided and on the first visit without any update, the following page is shown.
Figure 4: Initial page from the App Service.
It shows that you can deploy your web applications, from many sources, using many services such as FTP, Git etc. I will show you, how to do this using Git… There are a few other things that I would like to show you here,
I will show you how to do this, using git.
I will also show you, how to test the build integrity — whether build succeeds or not.
I will also show you, whether git considers to commit and push the changes to the server or not.
So these are a few of the tests that I have prepared for the automation tool that will be helpful for us in this case. These things are not provided on the tutorials that are available online, they are just simple straight-forward ones that only show you how to do it, not whether it is helpful to do it at all.
Setting up the local repository
On the machine side, the first thing to do is to set up a local repository for git deployments, even if you have created a project, you can still create a repository for that project and then use it as the source for your application’s content. So, for that, the following commands would work,
# If you have not created a project, remove these lines.
$ dotnet new -t web
$ dotnet restore
# The following creates a local repository
$ git init
This would create the project, set up the repository for us under .git directory. On my machine, the following was the result of this,
Figure 5: Creating a new project using .NET Core.
Not visible at the moment, however there is a special file called .gitignore, created by default and that contains really helpful ignore constraints for the git systems. However, we will look into them later as we progress.
Adding remote repositories
We can now set up a few remote repositories on own local machine so that once we need to publish the application, we don’t have to enter the URL of the repository every time. Instead, what we can do is, just call that alias of the repository and deploy the content there. This helps to notify the system of the locations where it needs to push the changes to. For that, first of all we need to setup our online repository to allow Local Git Deployments from Microsoft Azure and only then we can assure that we can send the code to the repository online. For that, head over to, Deployment options → Deployment source → Local git repository.
Figure 6: Deployment options in Microsoft Azure.
You can see that there are other options available too, select as required and wanted. I selected the third option so that we can publish the source code from our local machines to the servers in no time at all, without having to require any third-party vendors. You need to set up the credentials, so that when you are trying to publish the applications, only you are the one in charge of pushing the changes to the server and not anyone else.
Figure 7: Setting up credentials for the deployment account.
Once these things are set up, we can then move onwards to set up our local git programs to allow it to deploy the source code from our local environment all the way up to the Microsoft Azure. Stay with me. To do so, we need to execute the following command,
Note a few things in the previous command, the few things interesting here are that the repository always contains the name of your application service in the URL as well as in the resource file for your git processes. You need to update that, secondly, you need to update the username in the URL and as the one you used in the credentials (I used “afzaal” there). Once this is done, we can move onwards and actually push our first version of application to see, how Azure will behave.
In the previous commands, the first one takes care of the addition of files to the local tracking of the repository, to track the files that needs to be. Second command simply commits the changes and finally a push is made to the “repoinazure”, of course that is the repository where we will publish the application to.
Figure 8: Terminal asking for password before deployment.
It asks for the password and then continues to simply compress the objects, to deploy them using git protocol.
Figure 9: Terminal showing the progress.
The following is a screenshot of a process going on, during the first deployment. Next times and onwards it doesn’t take this much time and is very much simpler.
Figure 10: Terminal showing the processes going on at Azure during the deployment.
However, we will also create a shell script that automates the deployment for us. Once it is done, the terminal will show the following results on the screen and we can know that Azure is set up for startup.
Figure 11: Application deployed to Azure.
Let us navigate to the website and see if things are the way we are planning them to be.
Figure 12: Application’s home page after it has been uploaded to Azure.
Voila! We have finally deployed the application to the Azure. We now need to deploy the changes and so here is where I submit my recommendations, ideas and tips.
Development and redeployments
Let us add a simple controller to this web application, and then quickly deploy that using the script that we will create to do the trick for us. In this section, I will show you a simple ASP.NET Core Web API that will be used to basically see, how early an updates get published live on the server. So, I start with adding a new controller file to the web application’s source code and then modifying it to return a few objects with some data.
using System.Collections.Generic;
using Microsoft.AspNetCore.Mvc;
namespace WebApplication.Controllers {
[RouteAttribute("api/people")]
public class PersonApiController : Controller {
private List<Person> _people { get; set; } = new List<Person> {
new Person { ID = 1, Name = "Afzaal Ahmad Zeeshan" },
new Person { ID = 2, Name = "Bruce Wayne" },
new Person { ID = 3, Name = "Marshall Bruce Mathers III" }
};
public List<Person> GetPeople() {
return _people;
}
// Rest of the stuff here...
}
public class Person {
public int ID { get; set; }
public string Name { get; set; }
}
}
I just added a simple HTTP GET handler to show you how easy and simple it is to actually make the changes to your live application using git deployment from a local repository.
Now the magic trick for kids, the following script will manage most of our tasks and will take care of them before we proceed deploying the application.
if [ $# == 0 ]
then
echo "Usage: automate.sh <git-remote-repository>"
exit 1
fi
# Variables
commit_message="Deployment commit on $(date "+%B %dth, %Y at %H:%M %p")."
# Run the test
dotnet build
if [ $? == 0 ]
then
# Successful attempt.
# Update the git.
git add -A
echo "Using commit message, \"$commit_message\"."
git commit -m "$commit_message"
# Check if anything was commited, or whether there were no changes.
if [ $? == 0 ]
then
# Files need to be updated
# Update the azure's repository.
echo "Connecting to server for git push..."
git push $1 master
exit 0
else
echo "No changes to be pushed to server. Terminating."
exit 1
fi
exit
else
# There must have been an issue in the execution.
echo "There were errors in building process, fix them and re-try."
exit 1
fi
This would check if we are passing the remote repository or not, it will also build the project and then continue only if build succeeds. So, basically, this comes really handy when working with a terminal based environment especially Linux and using the git protocol for deployment. I recommend saving this as a file in your local repository, and then executing it from the terminal as a program. You can get the file from my GitHub repository too.
Figure 13: “autorun.sh” file available in the files.
Once this is done, simply create it executable and then finally execute the script to deploy it. It will go through each step and it will finally deploy the application, it would require password. I did not create the script to accept the password.
Figure 14: My script working and deploying the application to Azure.
So, let us run the system now. Once it is done, it will show you that you can now access the web application as it has been deployed successfully. Browser can confirm this,
Figure 15: Result of the deployment.
To see more information on this, we can head over to Azure to see how does the deployment affect our current source code.
Figure 16: Deployments shown on the Azure.
Clearly seen that now our most recent version of the deployment is being shown as the active deployment and the previous one is removed and set as Inactive. We can do deeper into them and change their status as needed but I won’t be doing that at all. Remember: Next time you want to publish the application, just use that script I provided.
Final words
Microsoft Azure provides very simple ways of deploying the applications, there are many other ways other than Git to deploy the applications to the server. OneDrive, GitHub and other cloud storage services can be used easily to deploy the applications.
However my major concern was to show how you can use the git, in a script-based environment to deploy the applications to Azure and also track when each commit gets pushed to the server. As you can see in this post, the commits are tracked on the cloud and you can change and select which commit you are interested in and set them as the active ones — such as in the case of a deletion of a file or so.